完全圖解GPT-2:看完這篇就夠了
原文:illustrated-gpt2
作者:Jay Alammar
機(jī)器之心編譯����,參與:郭元晨�����、陳韻瑩���、Geek AI��。
轉(zhuǎn)自:完全圖解GPT-2:看完這篇就夠了(一)、完全圖解GPT-2:看完這篇就夠了(二)
在過去的一年中,BERT�、Transformer XL����、XLNet 等大型自然語言處理模型輪番在各大自然語言處理任務(wù)排行榜上刷新最佳紀(jì)錄���,可謂你方唱罷我登場(chǎng)��。其中,GPT-2 由于其穩(wěn)定����、優(yōu)異的性能吸引了業(yè)界的關(guān)注���。
今年涌現(xiàn)出了許多機(jī)器學(xué)習(xí)的精彩應(yīng)用���,令人目不暇接,OpenAI 的 GPT-2 就是其中之一�。它在文本生成上有著驚艷的表現(xiàn)�����,其生成的文本在上下文連貫性和情感表達(dá)上都超過了人們對(duì)目前階段語言模型的預(yù)期���。僅從模型架構(gòu)而言��,GPT-2 并沒有特別新穎的架構(gòu),它和只帶有解碼器的 transformer 模型很像�。
然而��,GPT-2 有著超大的規(guī)模�,它是一個(gè)在海量數(shù)據(jù)集上訓(xùn)練的基于 transformer 的巨大模型。GPT-2 成功的背后究竟隱藏著什么秘密?本文將帶你一起探索取得優(yōu)異性能的 GPT-2 模型架構(gòu)��,重點(diǎn)闡釋其中關(guān)鍵的自注意力(self-attention)層��,并且看一看 GPT-2 采用的只有解碼器的 transformer 架構(gòu)在語言建模之外的應(yīng)用。
作者之前寫過一篇相關(guān)的介紹性文章「The Illustrated Transformer」����,本文將在其基礎(chǔ)上加入更多關(guān)于 transformer 模型內(nèi)部工作原理的可視化解釋����,以及這段時(shí)間以來關(guān)于 transformer 模型的新進(jìn)展�?��;?transformer 的模型在持續(xù)演進(jìn)�,我們希望本文使用的這一套可視化表達(dá)方法可以使此類模型更容易解釋�。
第一部分:GPT-2 和語言建模
首先���,究竟什么是語言模型(language model)����?
何為語言模型
簡(jiǎn)單說來�,語言模型的作用就是根據(jù)已有句子的一部分����,來預(yù)測(cè)下一個(gè)單詞會(huì)是什么。最著名的語言模型你一定見過,就是我們手機(jī)上的輸入法��,它可以根據(jù)當(dāng)前輸入的內(nèi)容智能推薦下一個(gè)詞����。
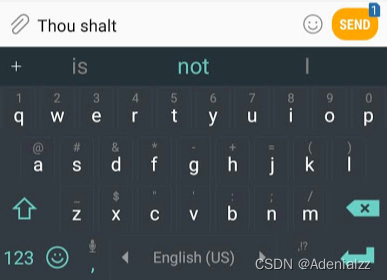
從這個(gè)意義上說,我們可以說 GPT-2 基本上相當(dāng)于輸入法的單詞聯(lián)想功能����,但它比你手機(jī)上安裝的此類應(yīng)用大得多,也更加復(fù)雜���。OpenAI 的研究人員使用了一個(gè)從網(wǎng)絡(luò)上爬取的 40GB 超大數(shù)據(jù)集「WebText」訓(xùn)練 GPT-2�,該數(shù)據(jù)集也是他們的工作成果的一部分�。
如果從占用存儲(chǔ)大小的角度進(jìn)行比較,我現(xiàn)在用的手機(jī)輸入法「SwiftKey」也就占用了 50MB 的空間,而 GPT-2 的最小版本也需要至少 500MB 的空間來存儲(chǔ)它的全部參數(shù)���,最大版本的 GPT-2 甚至需要超過 6.5GB 的存儲(chǔ)空間�����。

讀者可以用 AllenAI GPT-2 Explorer 來體驗(yàn) GPT-2 模型�����。它可以給出可能性排名前十的下一個(gè)單詞及其對(duì)應(yīng)概率���,你可以選擇其中一個(gè)單詞,然后看到下一個(gè)可能單詞的列表���,如此往復(fù)�����,最終完成一篇文章��。
使用 Transformers 進(jìn)行語言建模
正如本文作者在「The Illustrated Transformer 」這篇文章中所述�,原始的 transformer 模型由編碼器(encoder)和解碼器(decoder)組成�����,二者都是由被我們稱為「transformer 模塊」的部分堆疊而成����。這種架構(gòu)在機(jī)器翻譯任務(wù)中取得的成功證實(shí)了它的有效性���,值得一提的是�,這個(gè)任務(wù)之前效果最好的方法也是基于編碼器-解碼器架構(gòu)的���。
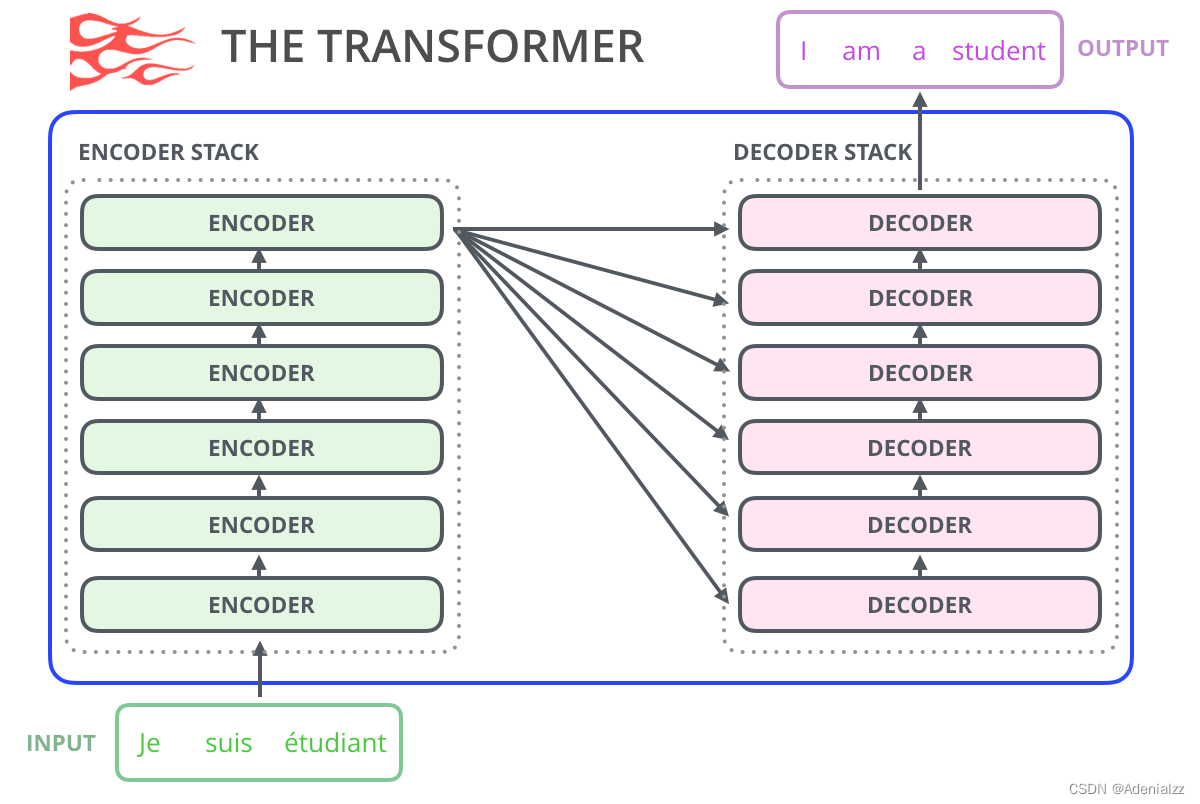
Transformer 的許多后續(xù)工作嘗試去掉編碼器或解碼器,也就是只使用一套堆疊得盡可能多的 transformer 模塊����,然后使用海量文本、耗費(fèi)大量的算力進(jìn)行訓(xùn)練(研究者往往要投入數(shù)十萬美元來訓(xùn)練這些語言模型����,而在 AlphaStar 項(xiàng)目中則可能要花費(fèi)數(shù)百萬美元)���。
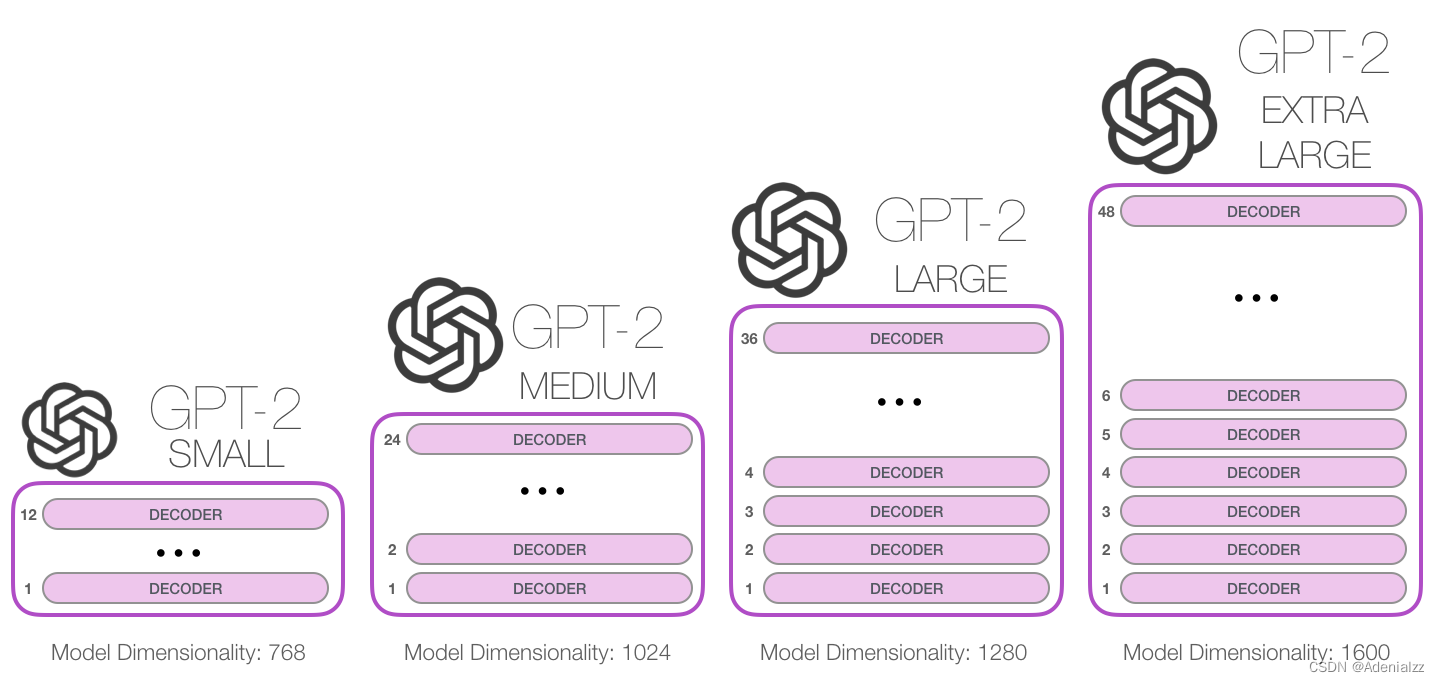
那么我們究竟能將這些模塊堆疊到多深呢�?事實(shí)上,這個(gè)問題的答案也就是區(qū)別不同 GPT-2 模型的主要因素之一,如下圖所示�?��!感√?hào)」的 GPT-2 模型堆疊了 12 層,「中號(hào)」24 層,「大號(hào)」36 層����,還有一個(gè)「特大號(hào)」堆疊了整整 48 層����。
與 BERT 的區(qū)別
First Law of Robotics
A robot may not injure a human being or, through inaction, allow a human being to come to harm.
機(jī)器人第一法則
機(jī)器人不得傷害人類���,或者目睹人類將遭受危險(xiǎn)而袖手旁觀����。
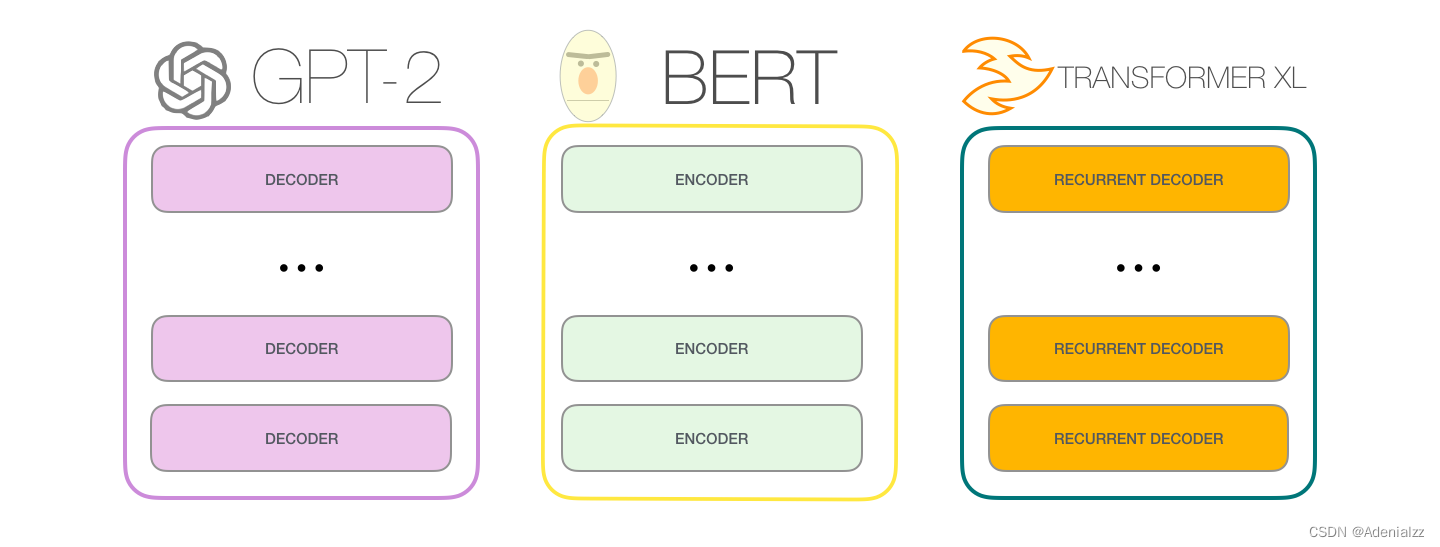
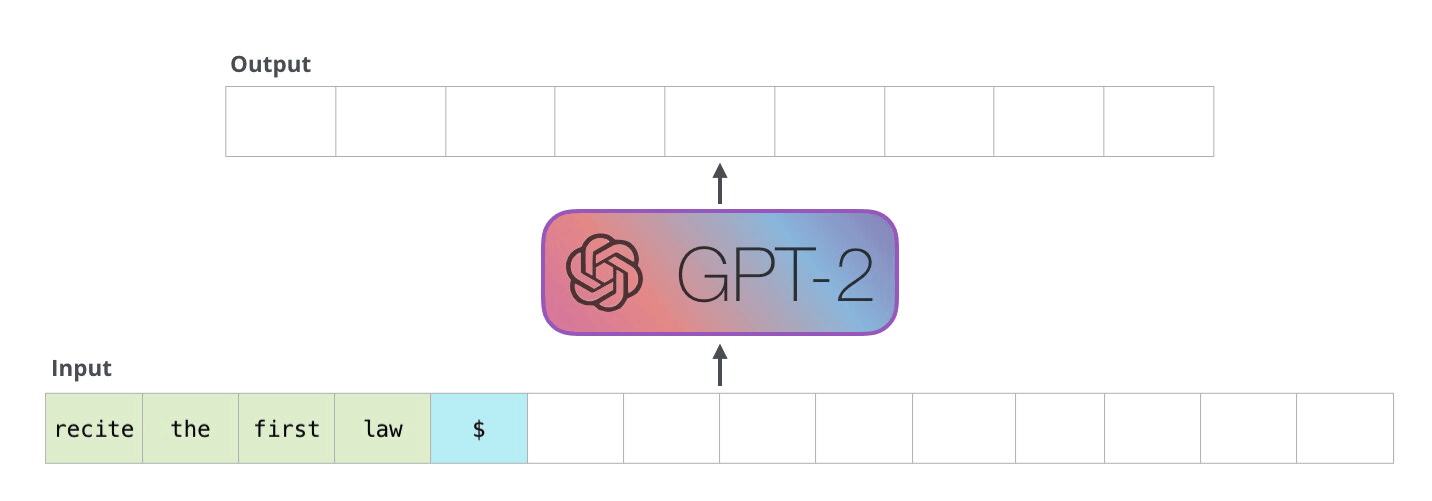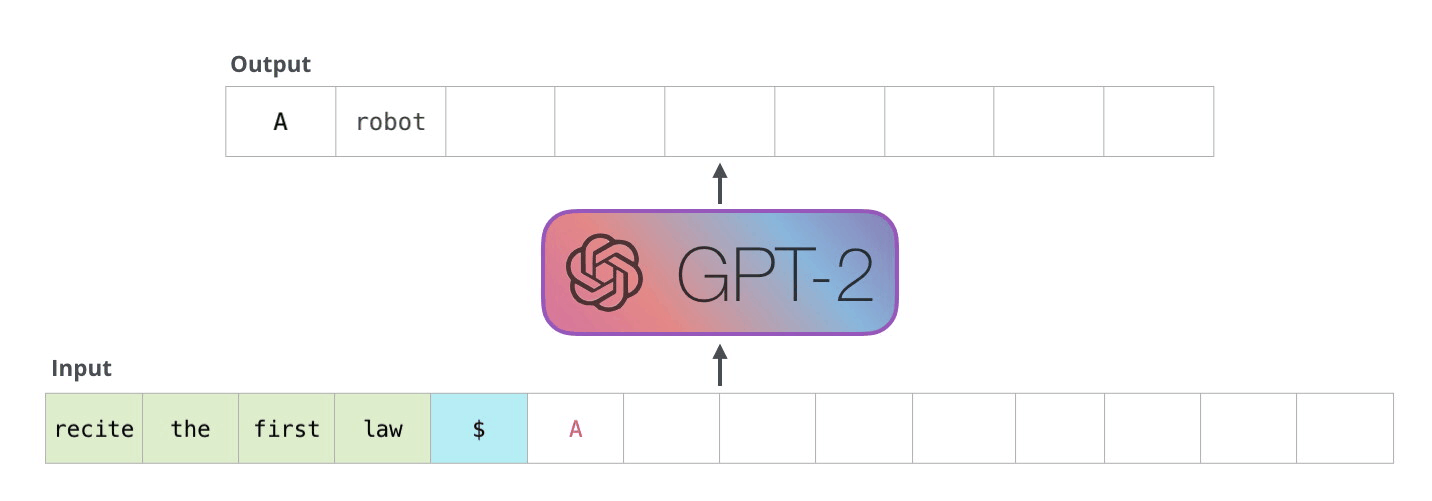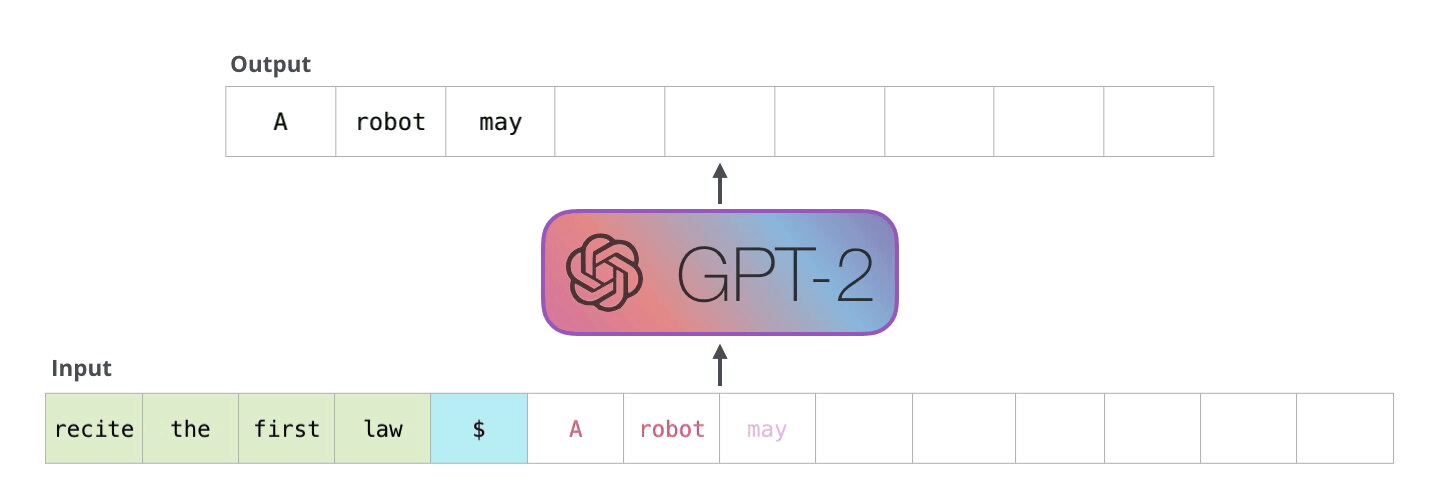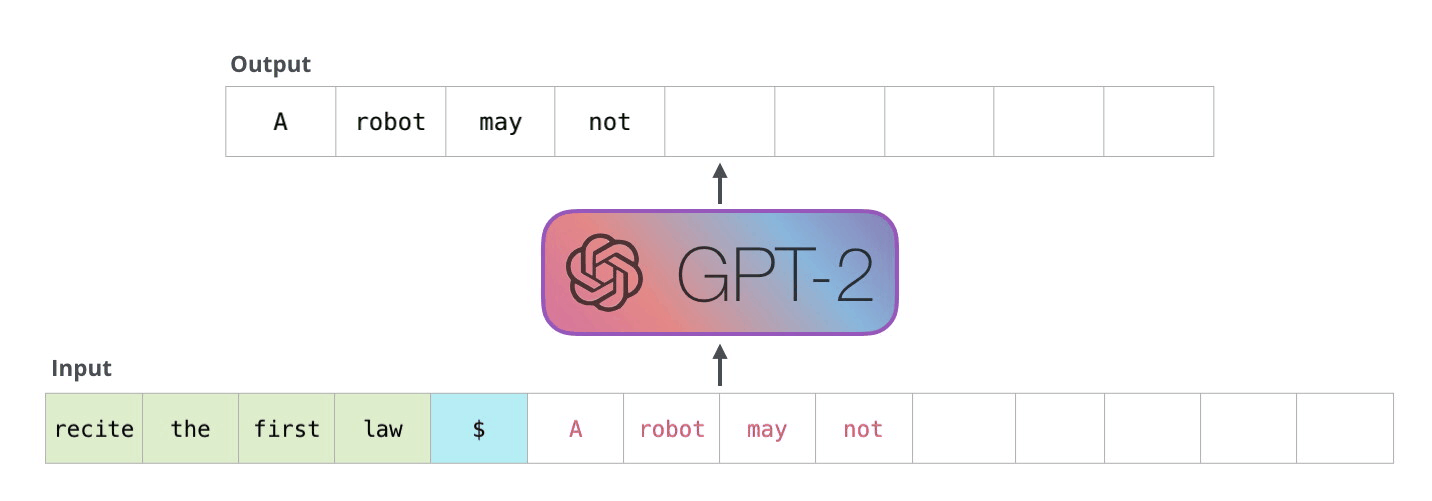
GPT-2 是使用「transformer 解碼器模塊」構(gòu)建的,而 BERT 則是通過「transformer 編碼器」模塊構(gòu)建的。我們將在下一節(jié)中詳述二者的區(qū)別��,但這里需要指出的是,二者一個(gè)很關(guān)鍵的不同之處在于:GPT-2 就像傳統(tǒng)的語言模型一樣,一次只輸出一個(gè)單詞(token)��。下面是引導(dǎo)訓(xùn)練好的模型「背誦」機(jī)器人第一法則的例子:
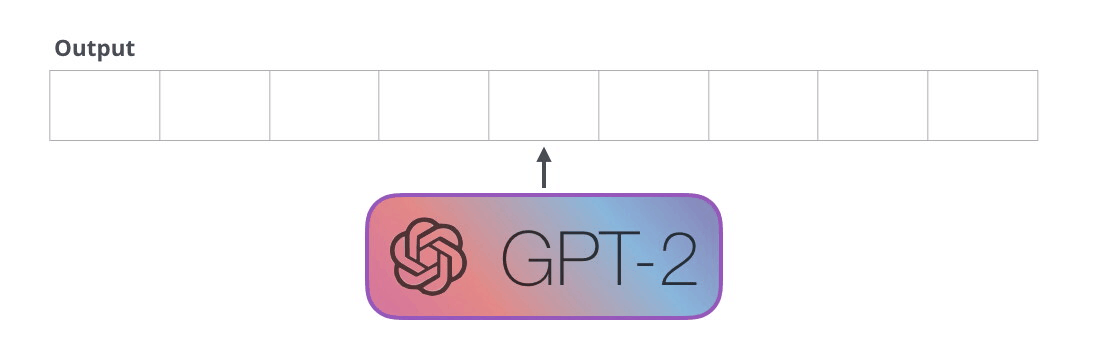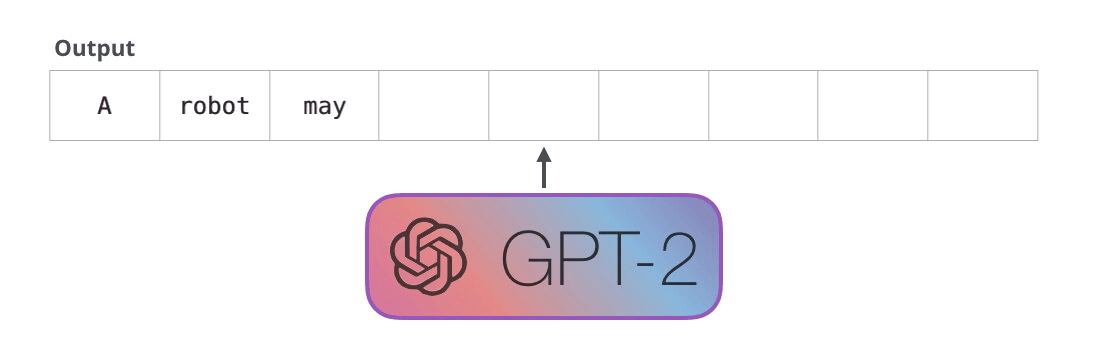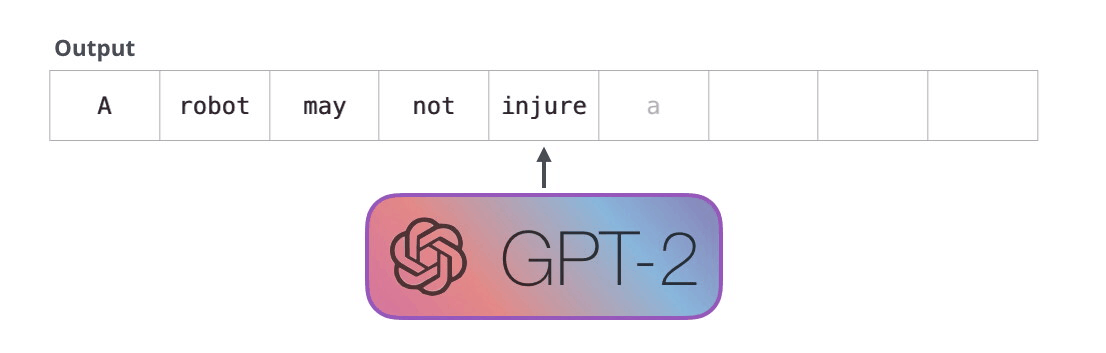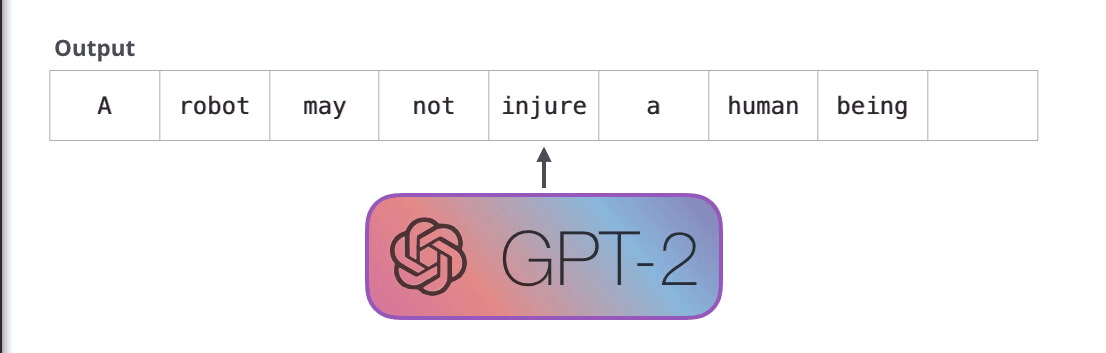
這種模型之所以效果好是因?yàn)樵诿總€(gè)新單詞產(chǎn)生后��,該單詞就被添加在之前生成的單詞序列后面�����,這個(gè)序列會(huì)成為模型下一步的新輸入��。這種機(jī)制叫做自回歸(auto-regression),同時(shí)也是令 RNN 模型效果拔群的重要思想�。
GPT-2,以及一些諸如 TransformerXL 和 XLNet 等后續(xù)出現(xiàn)的模型��,本質(zhì)上都是自回歸模型��,而 BERT 則不然�����。這就是一個(gè)權(quán)衡的問題了�����。雖然沒有使用自回歸機(jī)制���,但 BERT 獲得了結(jié)合單詞前后的上下文信息的能力,從而取得了更好的效果。XLNet 使用了自回歸��,并且引入了一種能夠同時(shí)兼顧前后的上下文信息的方法。
Transformer 模塊的演進(jìn)
原始的 transformer 論文引入了兩種類型的 transformer 模塊,分別是:編碼器模塊和解碼器模塊����。
編碼器模塊
首先是編碼器(encoder)模塊:
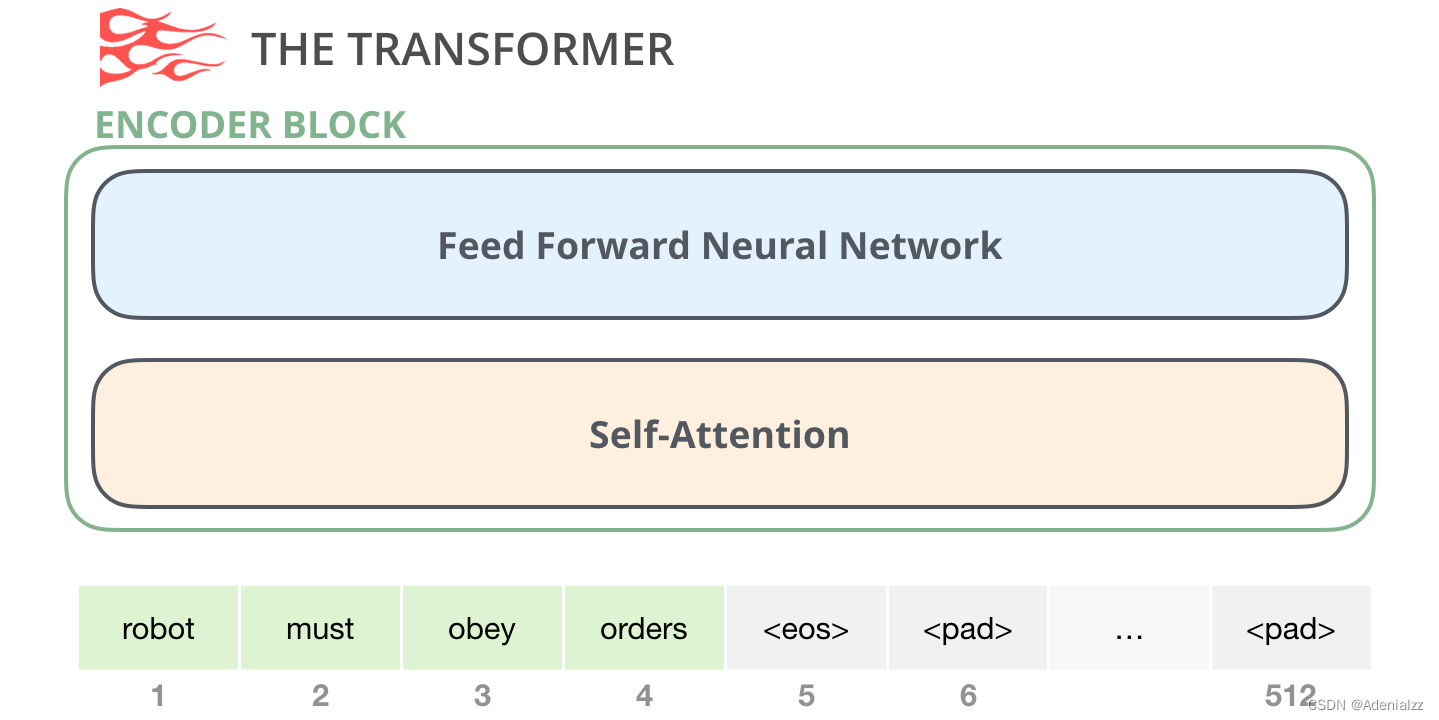
原始 transformer 論文中的編碼器模塊可以接受長(zhǎng)度不超過最大序列長(zhǎng)度(如 512 個(gè)單詞)的輸入���。如果序列長(zhǎng)度小于該限制,我們就在其后填入預(yù)先定義的空白單詞(如上圖中的 <pad>)�。
解碼器模塊
其次是解碼器模塊���,它與編碼器模塊在架構(gòu)上有一點(diǎn)小差異——加入了一層使得它可以重點(diǎn)關(guān)注編碼器輸出的某一片段,也就是下圖中的編碼器-解碼器自注意力(encoder-decoder self-attention)層。
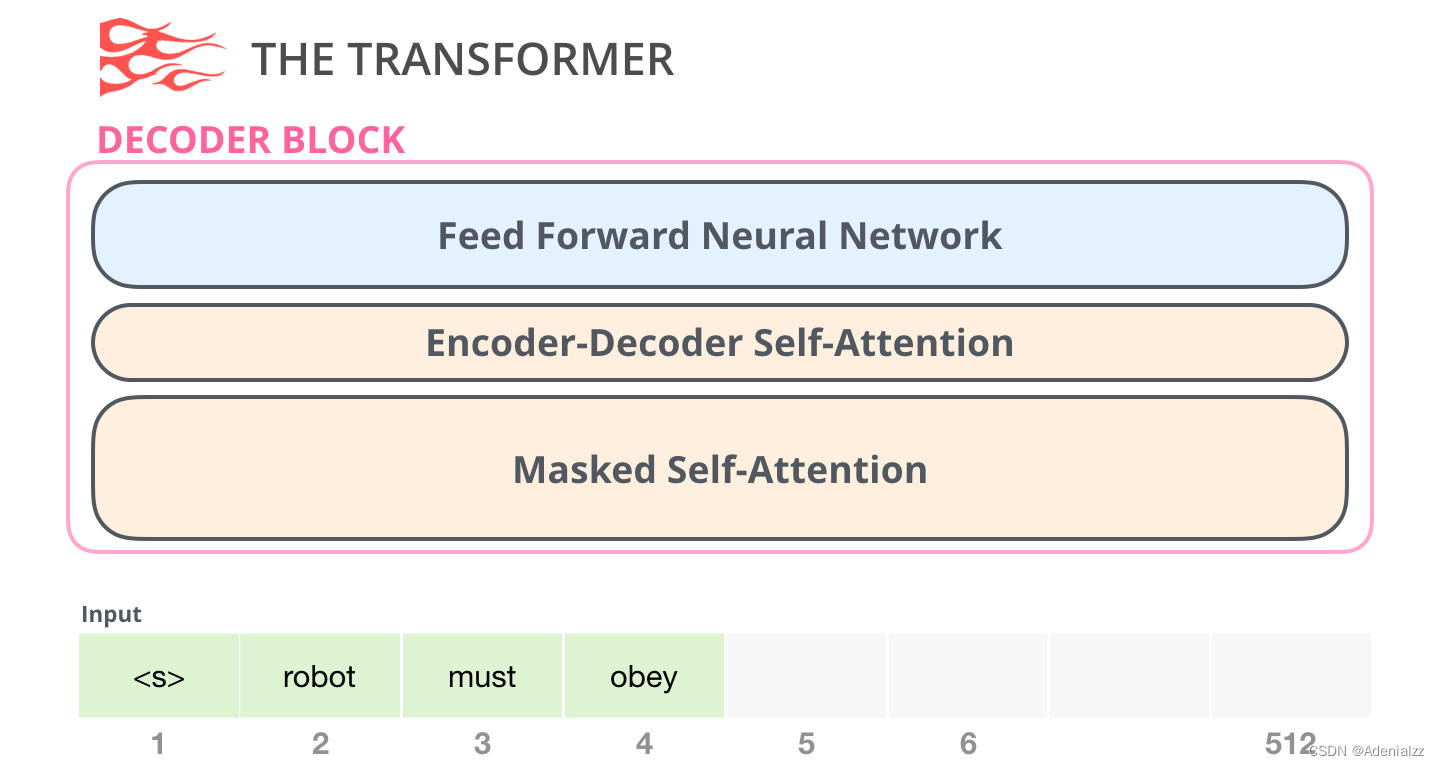
解碼器在自注意力(self-attention)層上還有一個(gè)關(guān)鍵的差異:它將后面的單詞掩蓋掉了����。但并不像 BERT 一樣將它們替換成特殊定義的單詞 <mask>��,而是在自注意力計(jì)算的時(shí)候屏蔽了來自當(dāng)前計(jì)算位置右邊所有單詞的信息��。
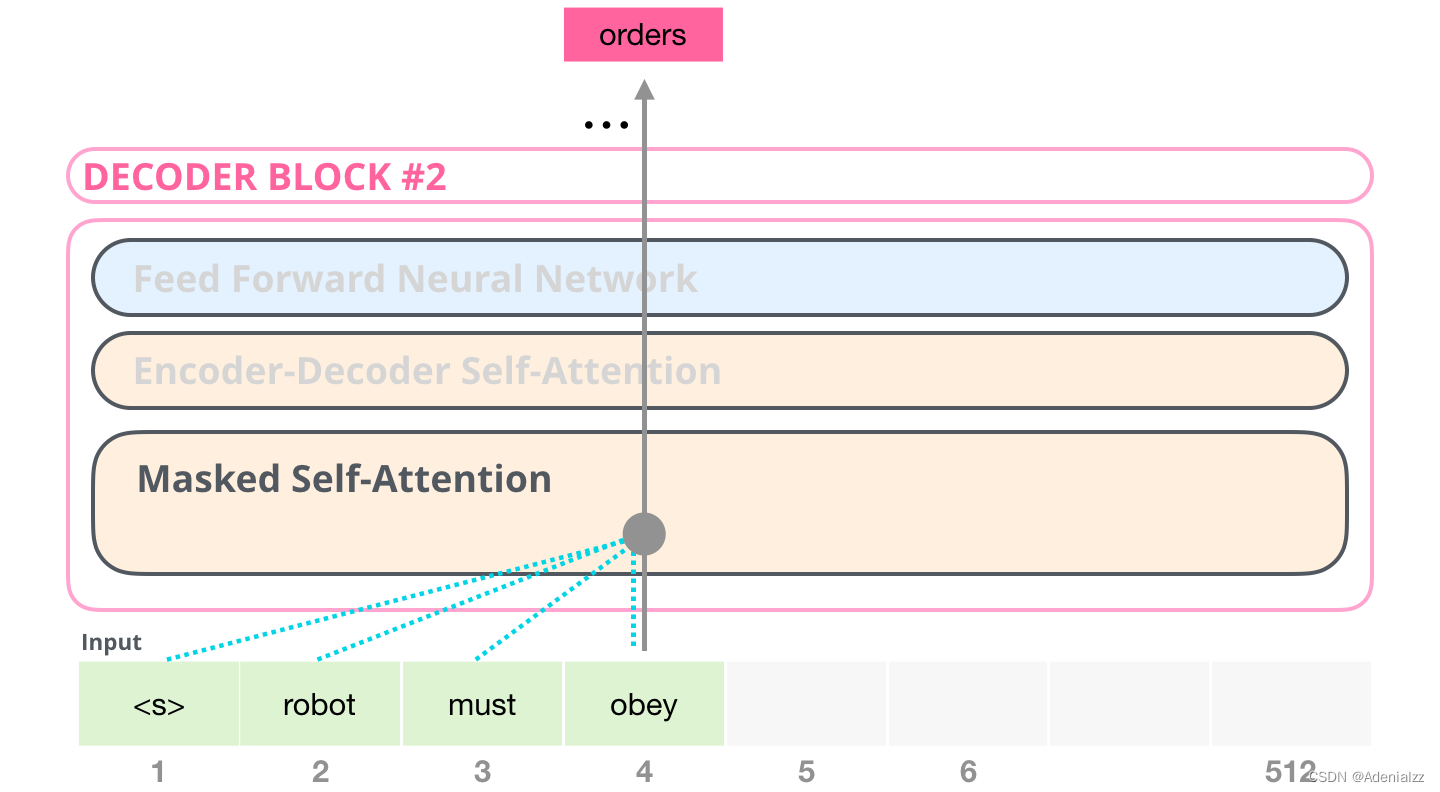
舉個(gè)例子��,如果我們重點(diǎn)關(guān)注 4 號(hào)位置單詞及其前續(xù)路徑�����,我們可以模型只允許注意當(dāng)前計(jì)算的單詞以及之前的單詞:
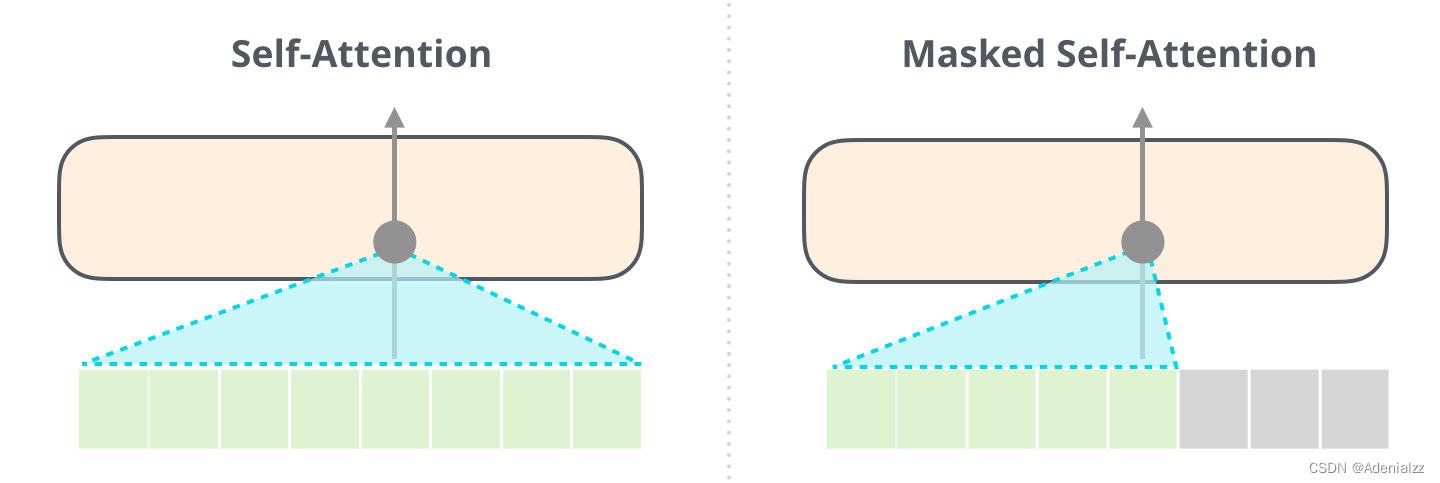
能夠清楚地區(qū)分 BERT 使用的自注意力(self-attention)模塊和 GPT-2 使用的帶掩模的自注意力(masked self-attention)模塊很重要�����。普通的自注意力模塊允許一個(gè)位置看到它右側(cè)單詞的信息(如下左圖),而帶掩模的自注意力模塊則不允許這么做(如下右圖)��。
只包含解碼器的模塊
在 transformer 原始論文發(fā)表之后����,一篇名為「Generating Wikipedia by Summarizing Long Sequences」的論文提出用另一種 transformer 模塊的排列方式來進(jìn)行語言建?��!苯尤拥袅怂械?transformer 編碼器模塊……我們姑且就管它叫做「Transformer-Decoder」模型吧����。這個(gè)早期的基于 transformer 的模型由 6 個(gè) transformer 解碼器模塊堆疊而成:
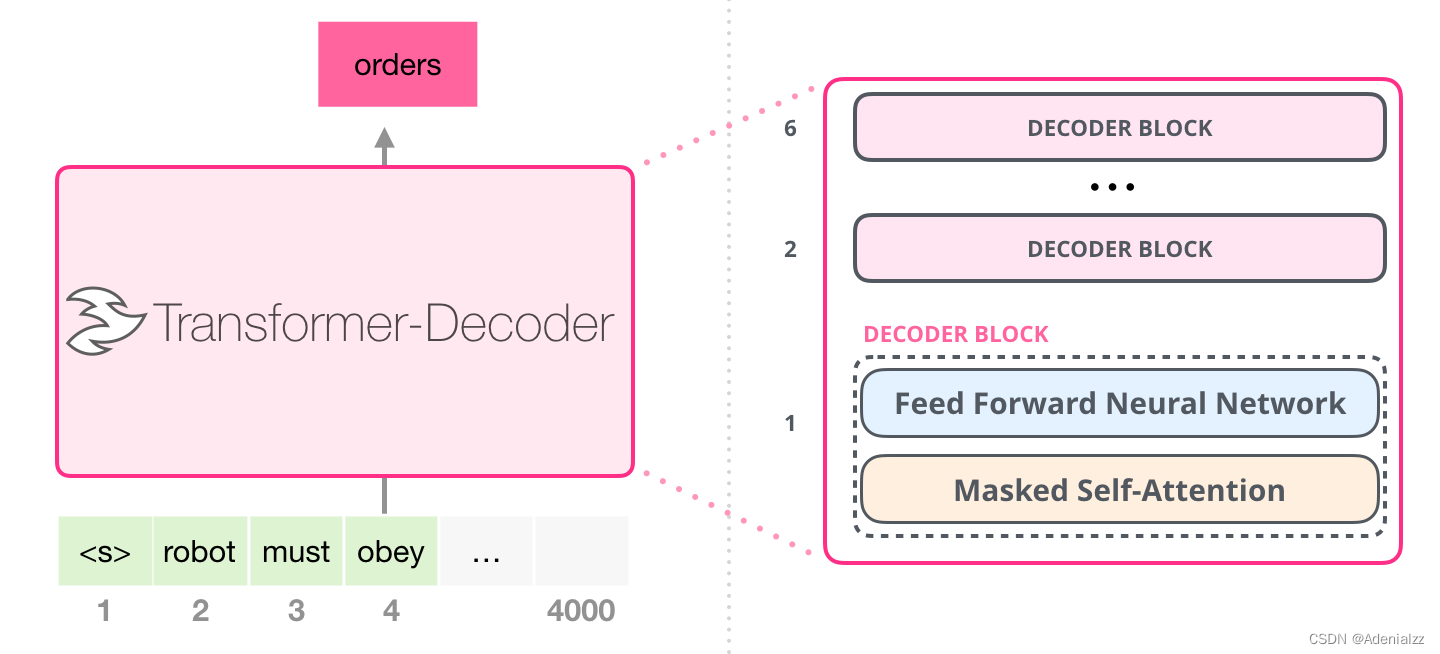
圖中所有的解碼器模塊都是一樣的�����,因此本文只展開了第一個(gè)解碼器的內(nèi)部結(jié)構(gòu)���?�?梢钥匆姡褂昧藥а谀5淖宰⒁饬?����。請(qǐng)注意,該模型在某個(gè)片段中可以支持最長(zhǎng) 4000 個(gè)單詞的序列����,相較于 transformer 原始論文中最長(zhǎng) 512 單詞的限制有了很大的提升�。
這些解碼器模塊和 transformer 原始論文中的解碼器模塊相比���,除了去除了第二個(gè)自注意力層之外��,并無很大不同。一個(gè)相似的架構(gòu)在字符級(jí)別的語言建模中也被驗(yàn)證有效����,它使用更深的自注意力層構(gòu)建語言模型��,一次預(yù)測(cè)一個(gè)字母/字符�����。
OpenAI 的 GPT-2 模型就用了這種只包含編碼器(decoder-only)的模塊���。
GPT-2 內(nèi)部機(jī)制速成
Look inside and you will see, The words are cutting deep inside my brain. Thunder burning, quickly burning, Knife of words is driving me insane, insane yeah. ——Budgie
在我內(nèi)心����,字字如刀;電閃雷鳴�����,使我瘋癲?��!狟udgie
接下來�,我們將深入剖析 GPT-2 的內(nèi)部結(jié)構(gòu),看看它是如何工作的�。
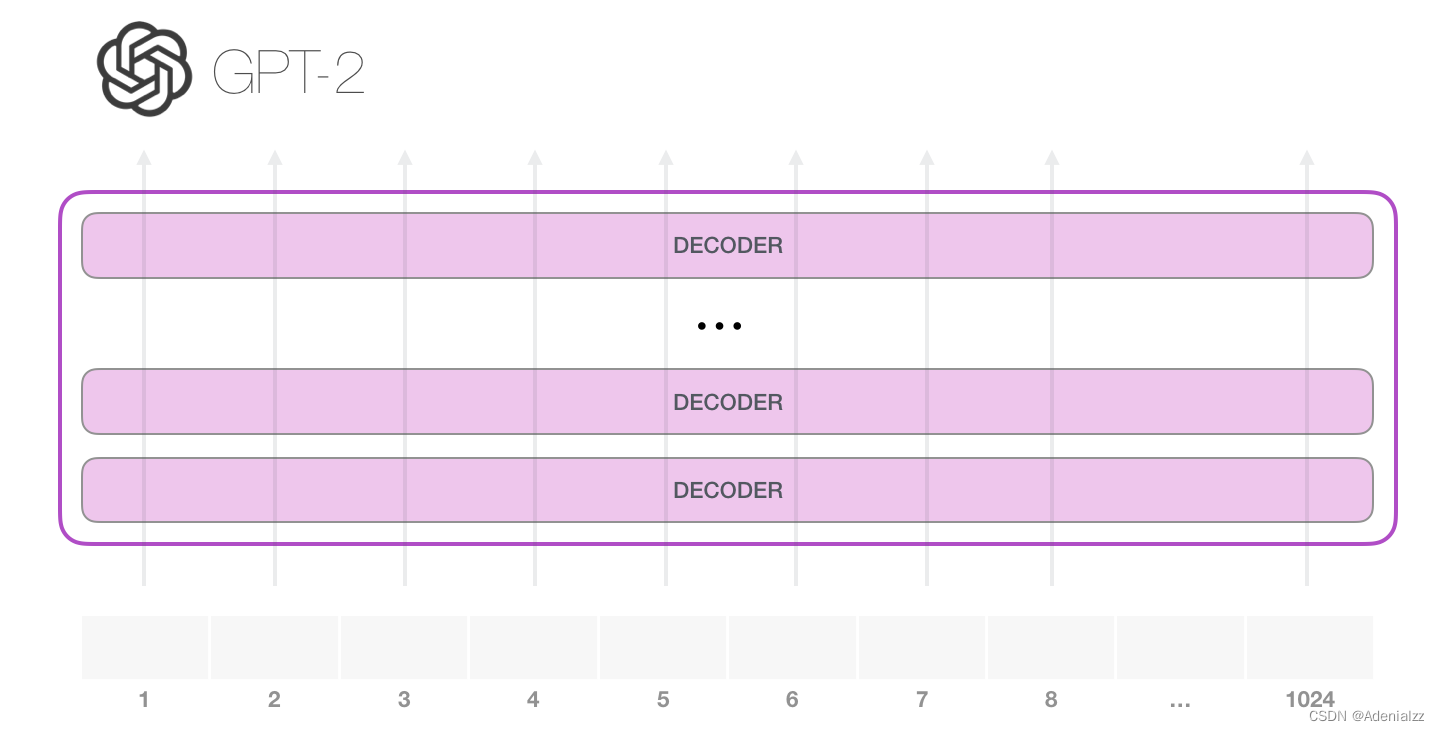
GPT-2 可以處理最長(zhǎng) 1024 個(gè)單詞的序列�����。每個(gè)單詞都會(huì)和它的前續(xù)路徑一起「流過」所有的解碼器模塊。
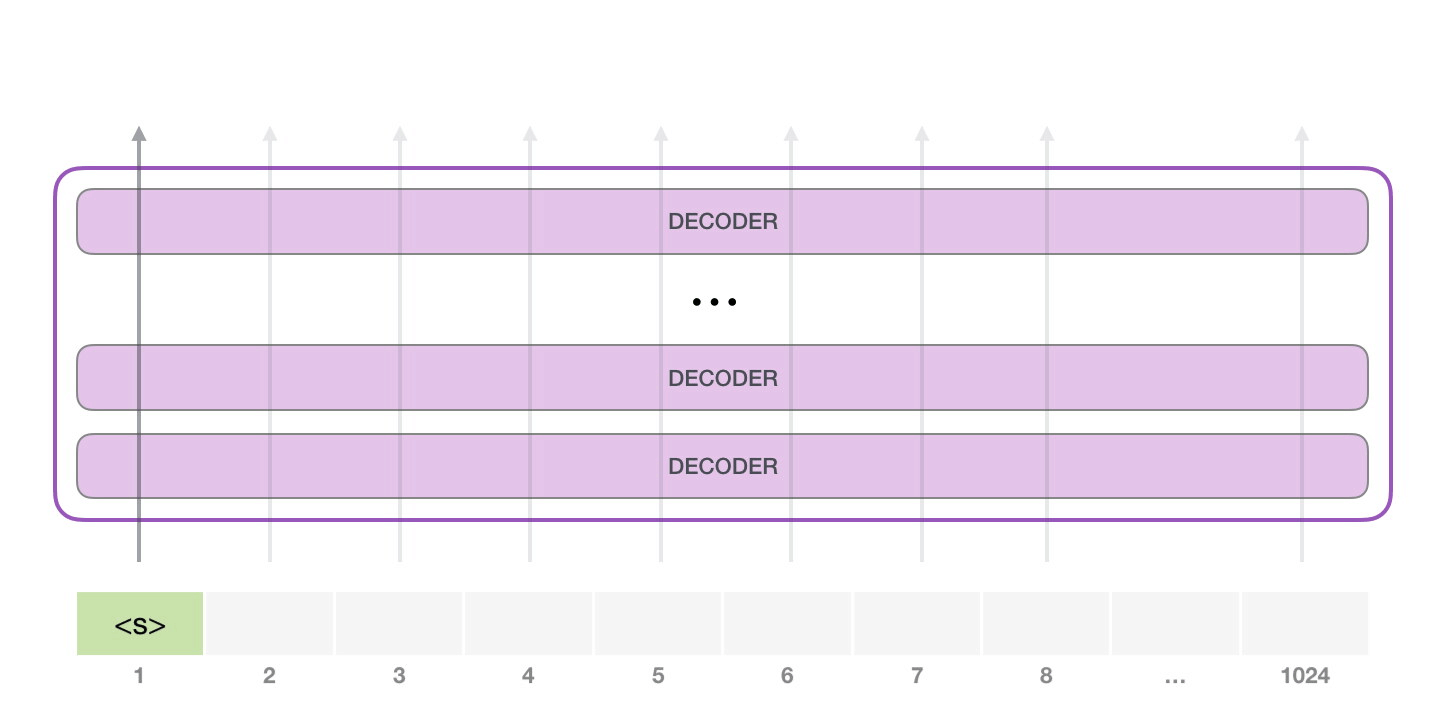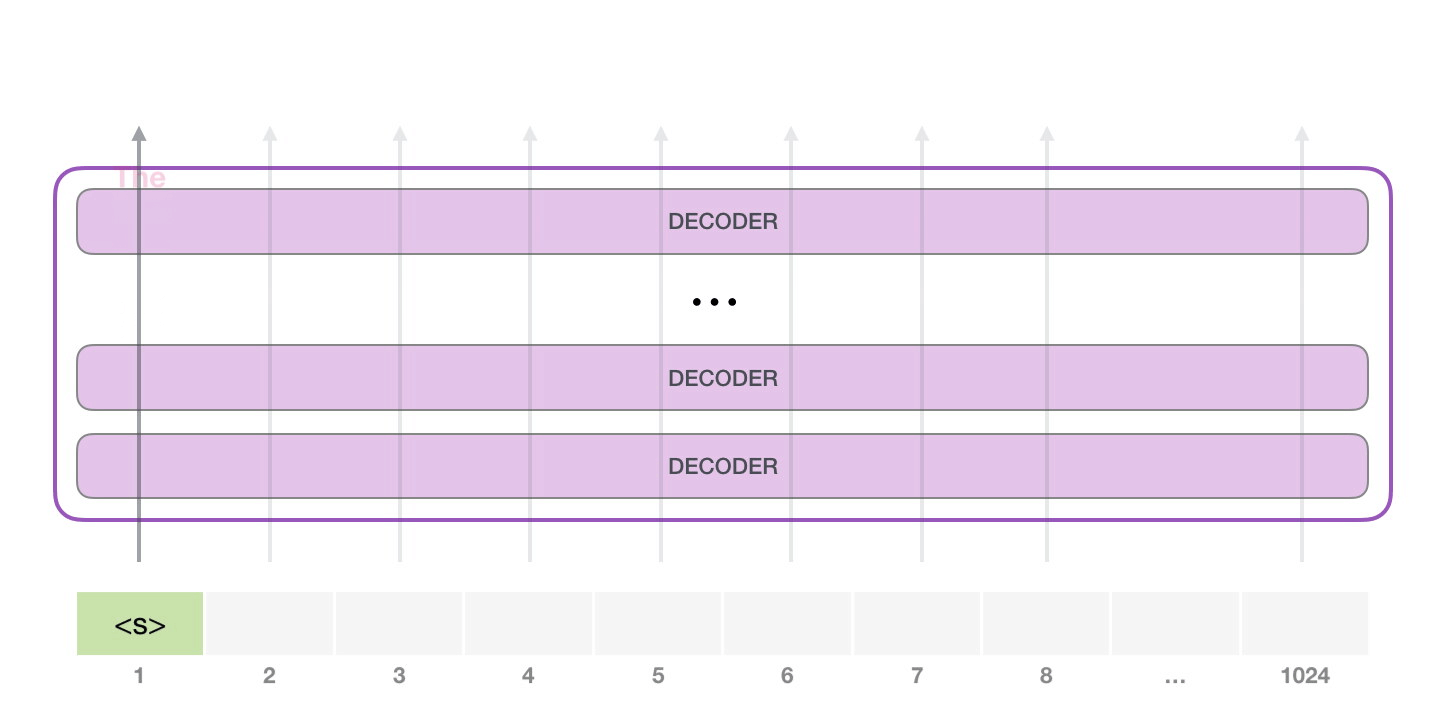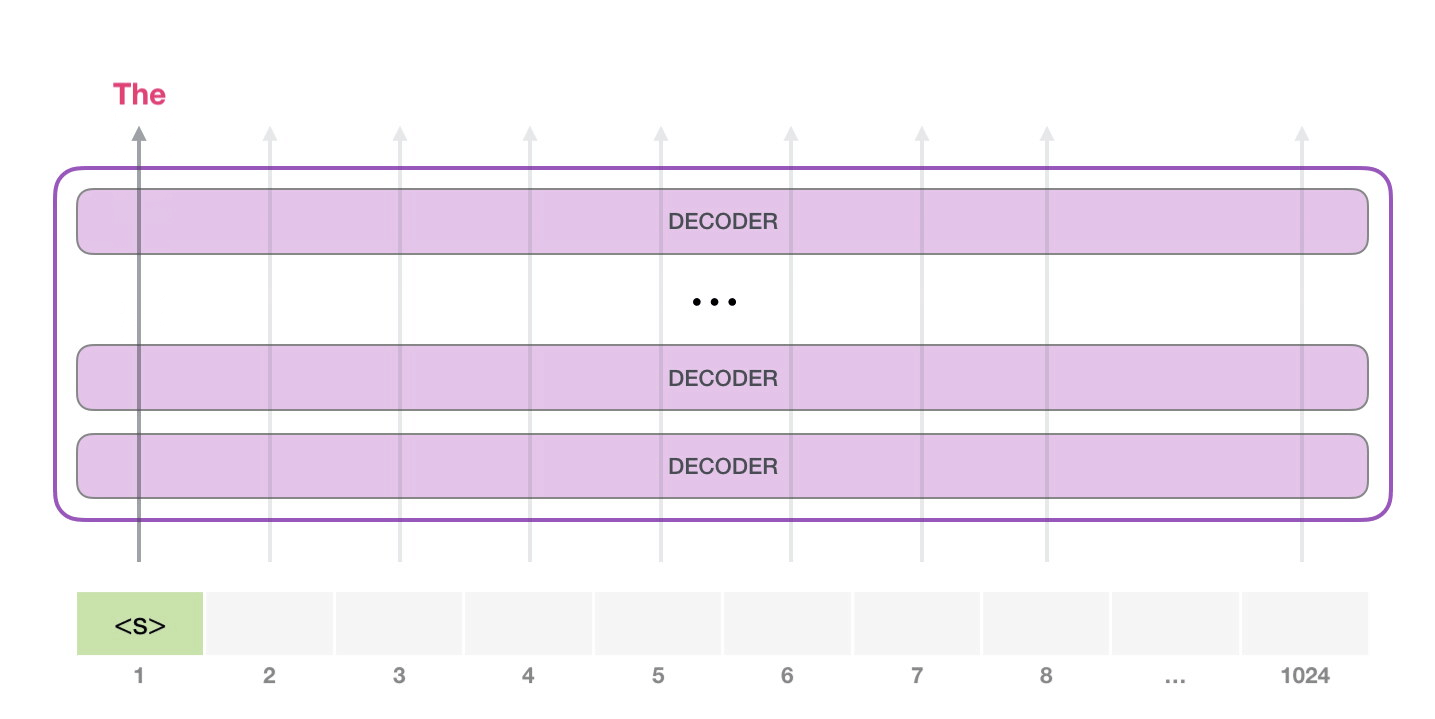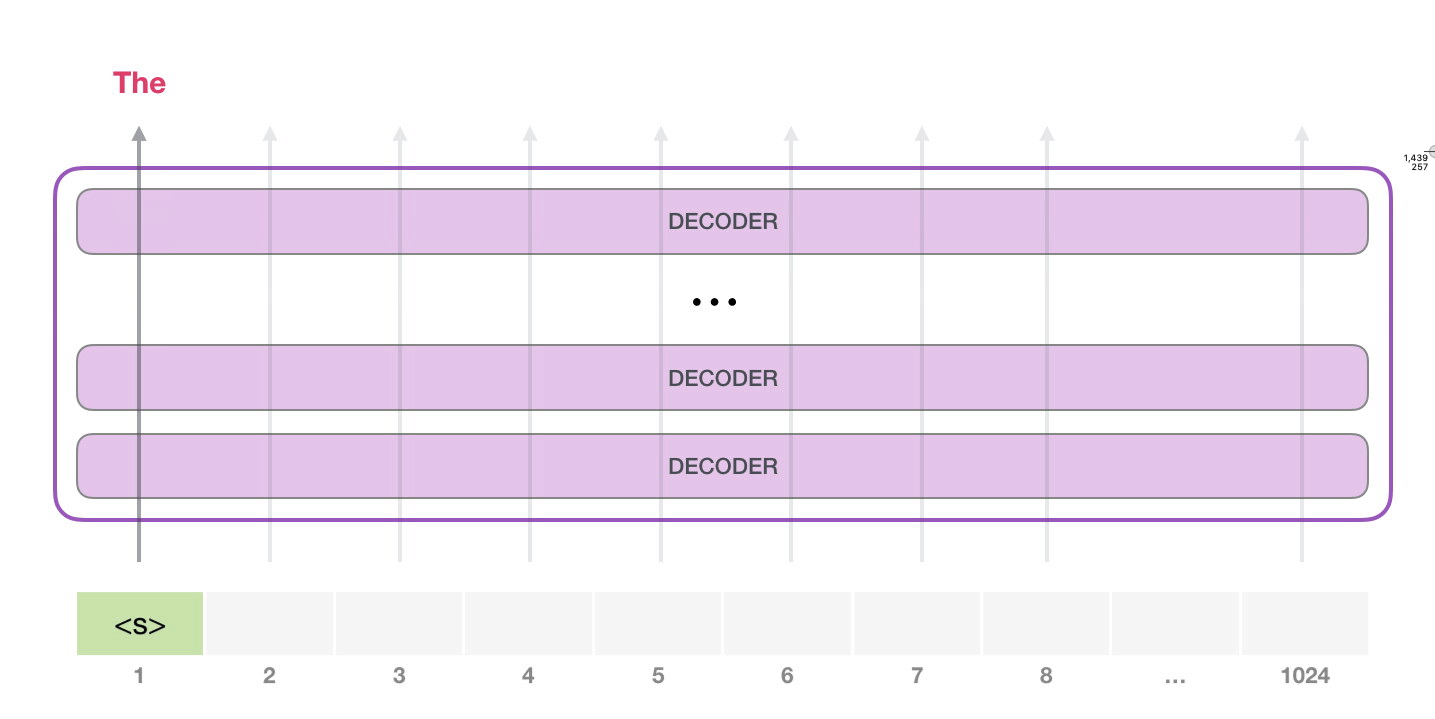
想要運(yùn)行一個(gè)訓(xùn)練好的 GPT-2 模型��,最簡(jiǎn)單的方法就是讓它自己隨機(jī)工作(從技術(shù)上說�����,叫做生成無條件樣本)�����。換句話說�����,我們也可以給它一點(diǎn)提示,讓它說一些關(guān)于特定主題的話(即生成交互式條件樣本)�����。在隨機(jī)情況下,我們只簡(jiǎn)單地提供一個(gè)預(yù)先定義好的起始單詞(訓(xùn)練好的模型使用 <|endoftext|> 作為它的起始單詞���,不妨將其稱為 <s>)����,然后讓它自己生成文字�����。
此時(shí),模型的輸入只有一個(gè)單詞�����,所以只有這個(gè)單詞的路徑是活躍的。單詞經(jīng)過層層處理�����,最終得到一個(gè)向量。向量可以對(duì)于詞匯表的每個(gè)單詞計(jì)算一個(gè)概率(詞匯表是模型能「說出」的所有單詞����,GPT-2 的詞匯表中有 50000 個(gè)單詞)�����。在本例中�����,我們選擇概率最高的單詞「The」作為下一個(gè)單詞��。
但有時(shí)這樣會(huì)出問題——就像如果我們持續(xù)點(diǎn)擊輸入法推薦單詞的第一個(gè),它可能會(huì)陷入推薦同一個(gè)詞的循環(huán)中�,只有你點(diǎn)擊第二或第三個(gè)推薦詞�,才能跳出這種循環(huán)����。同樣的�,GPT-2 也有一個(gè)叫做「top-k」的參數(shù),模型會(huì)從概率前 k 大的單詞中抽樣選取下一個(gè)單詞。顯然���,在之前的情況下��,top-k = 1。
接下來��,我們將輸出的單詞添加在輸入序列的尾部構(gòu)建新的輸入序列�,讓模型進(jìn)行下一步的預(yù)測(cè):
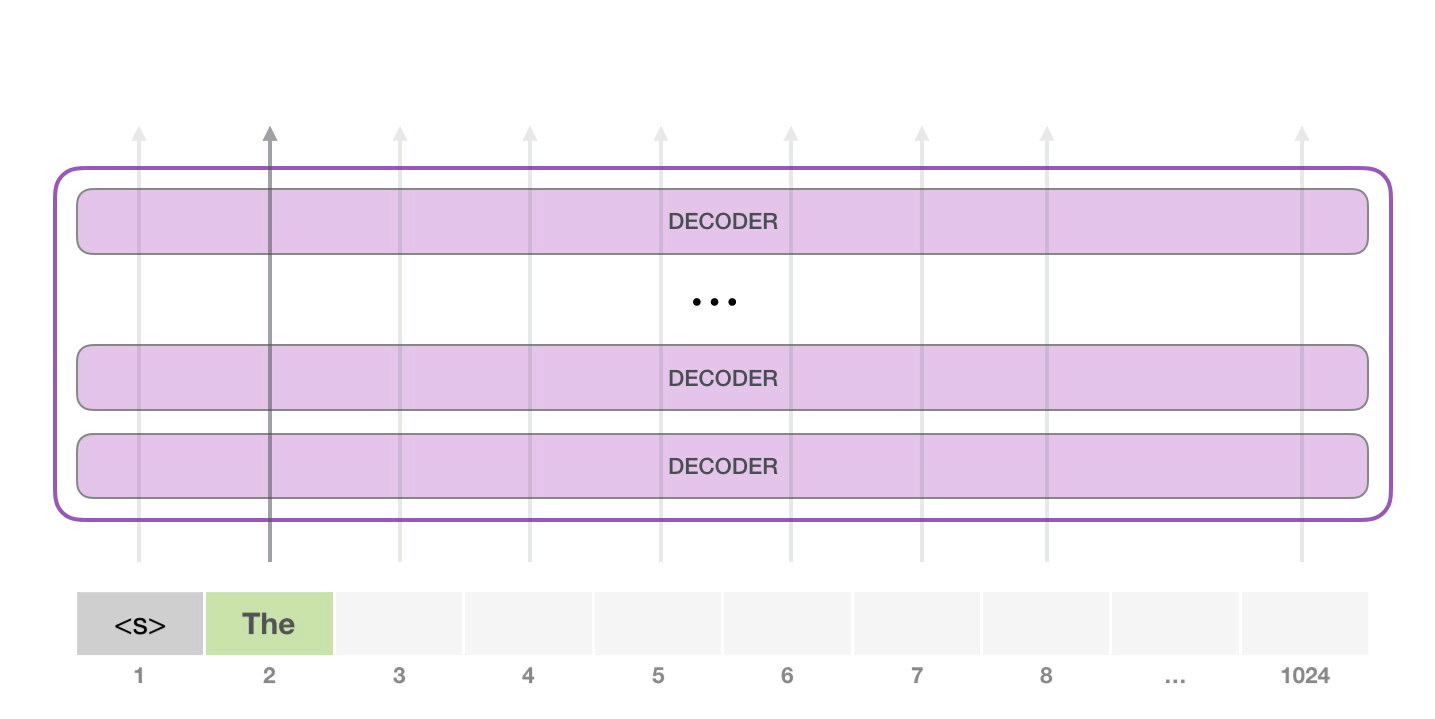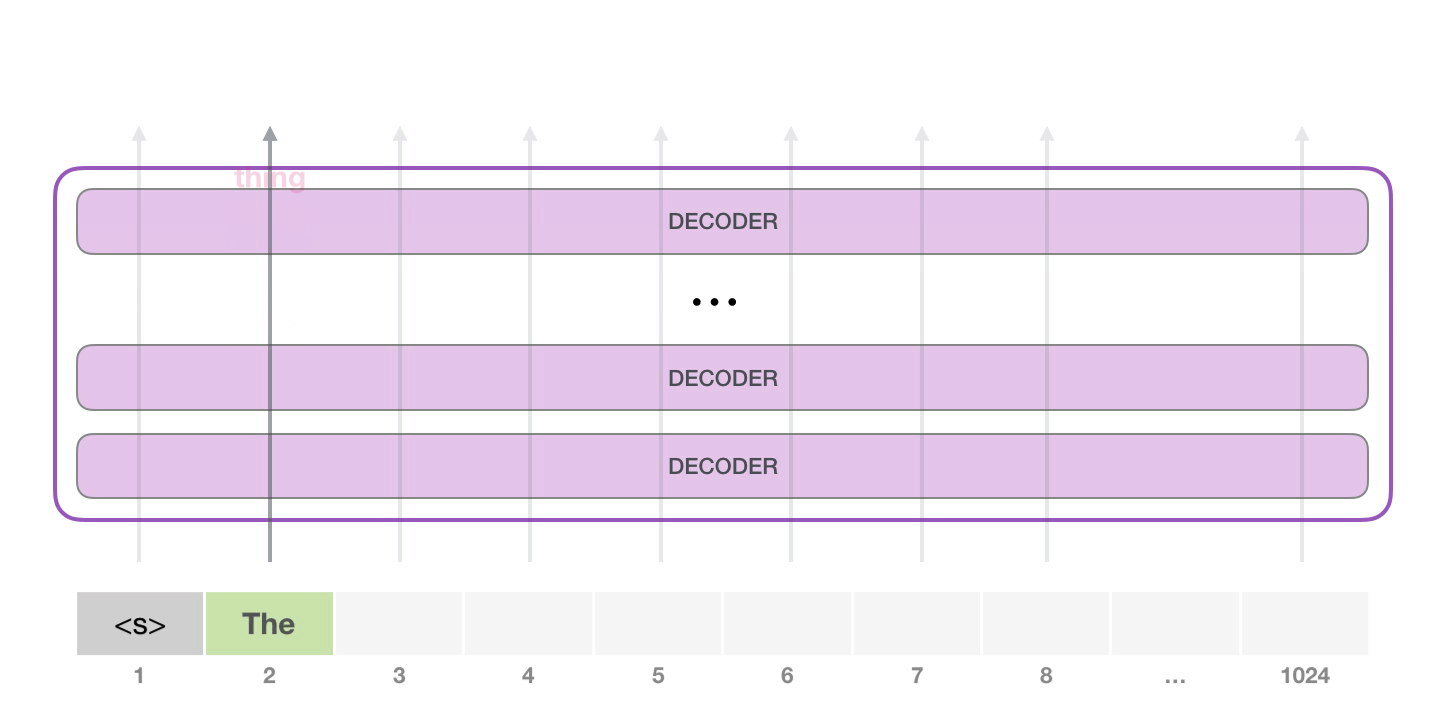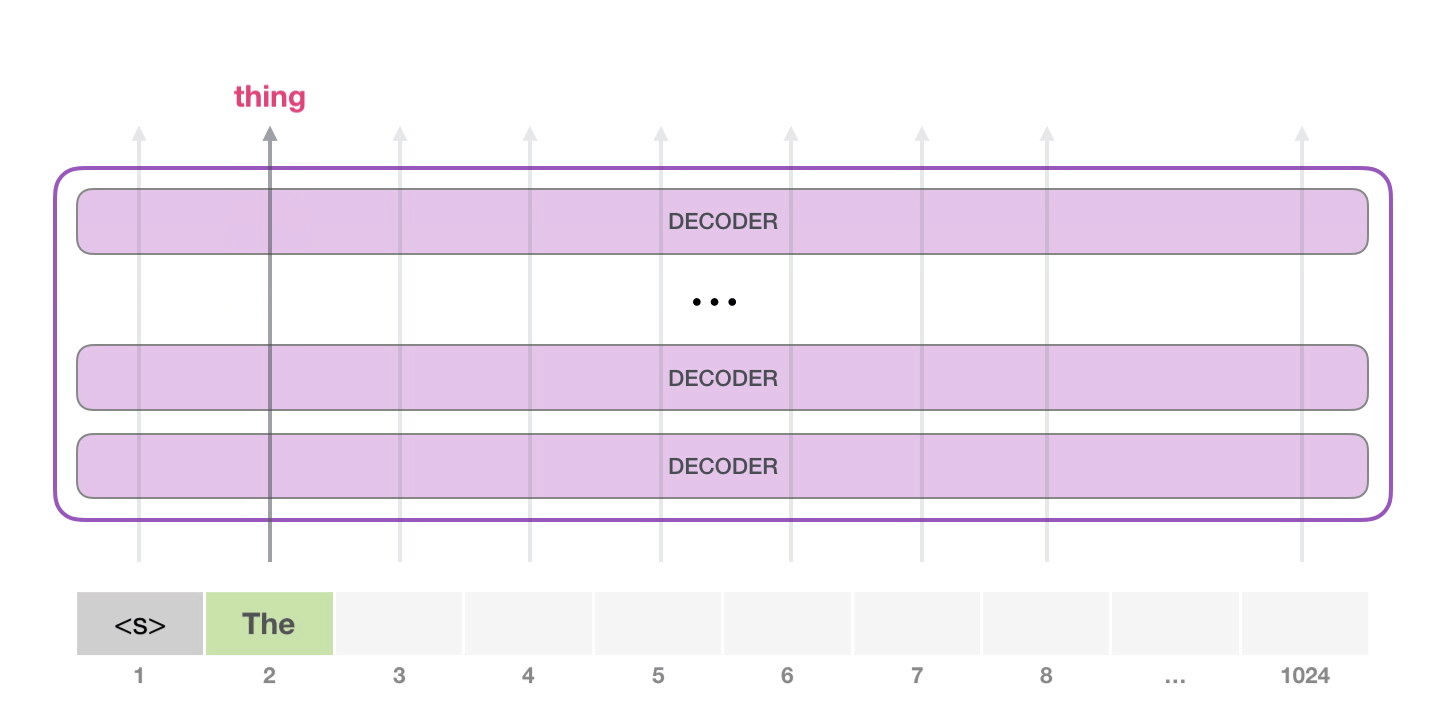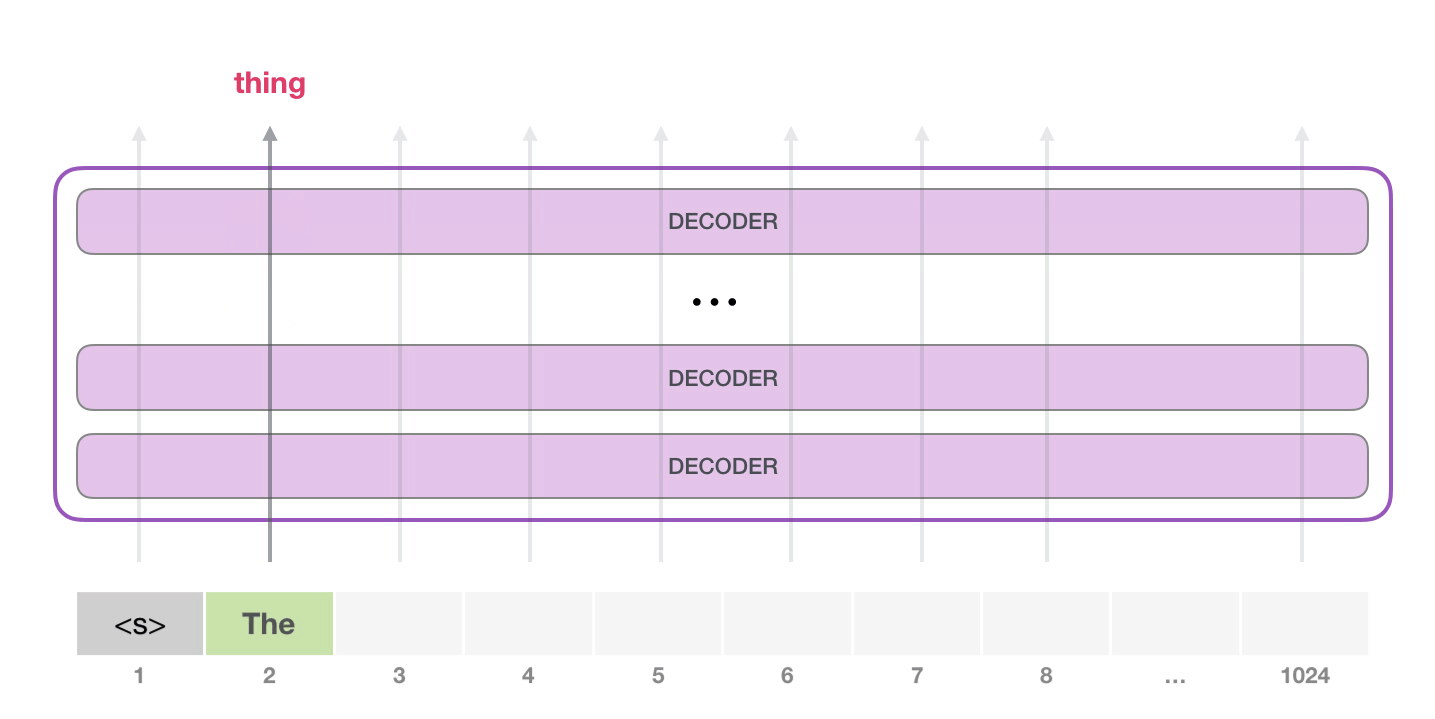
請(qǐng)注意����,第二個(gè)單詞的路徑是當(dāng)前唯一活躍的路徑了�。GPT-2 的每一層都保留了它們對(duì)第一個(gè)單詞的解釋�����,并且將運(yùn)用這些信息處理第二個(gè)單詞(具體將在下面一節(jié)對(duì)自注意力機(jī)制的講解中詳述),GPT-2 不會(huì)根據(jù)第二個(gè)單詞重新解釋第一個(gè)單詞。
更加深入了解內(nèi)部原理
輸入編碼
讓我們更加深入地了解一下模型的內(nèi)部細(xì)節(jié)�。首先�,讓我們從模型的輸入開始��。正如我們之前討論過的其它自然語言處理模型一樣,GPT-2 同樣從嵌入矩陣中查找單詞對(duì)應(yīng)的嵌入向量,該矩陣也是模型訓(xùn)練結(jié)果的一部分���。
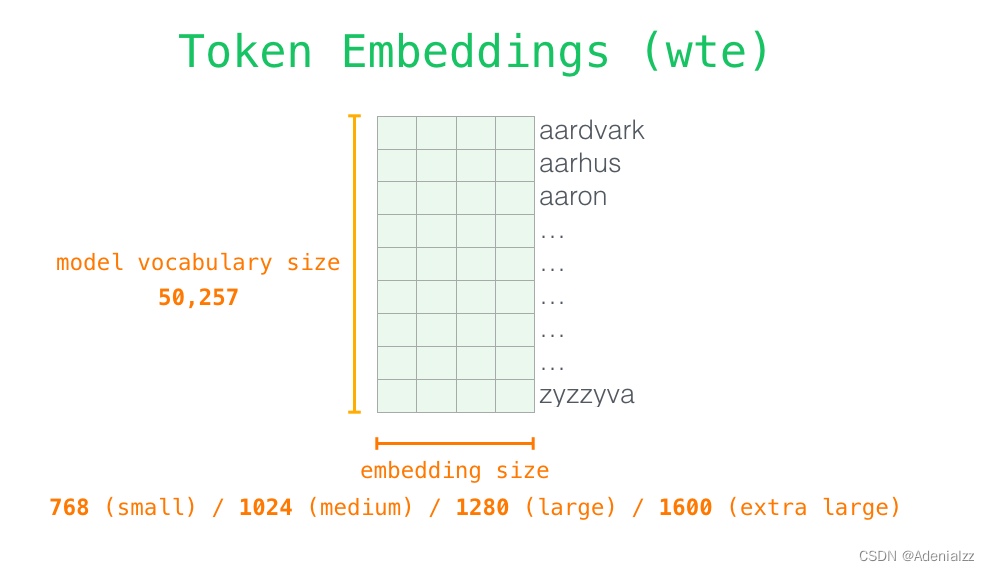
每一行都是一個(gè)詞嵌入向量:一個(gè)能夠表征某個(gè)單詞�,并捕獲其意義的數(shù)字列表。嵌入向量的長(zhǎng)度和 GPT-2 模型的大小有關(guān)�,最小的模型使用了長(zhǎng)為 768 的嵌入向量來表征一個(gè)單詞�����。
所以在一開始��,我們需要在嵌入矩陣中查找起始單詞 <s> 對(duì)應(yīng)的嵌入向量。但在將其輸入給模型之前�,我們還需要引入位置編碼——一些向 transformer 模塊指出序列中的單詞順序的信號(hào)�����。1024 個(gè)輸入序列位置中的每一個(gè)都對(duì)應(yīng)一個(gè)位置編碼,這些編碼組成的矩陣也是訓(xùn)練模型的一部分����。
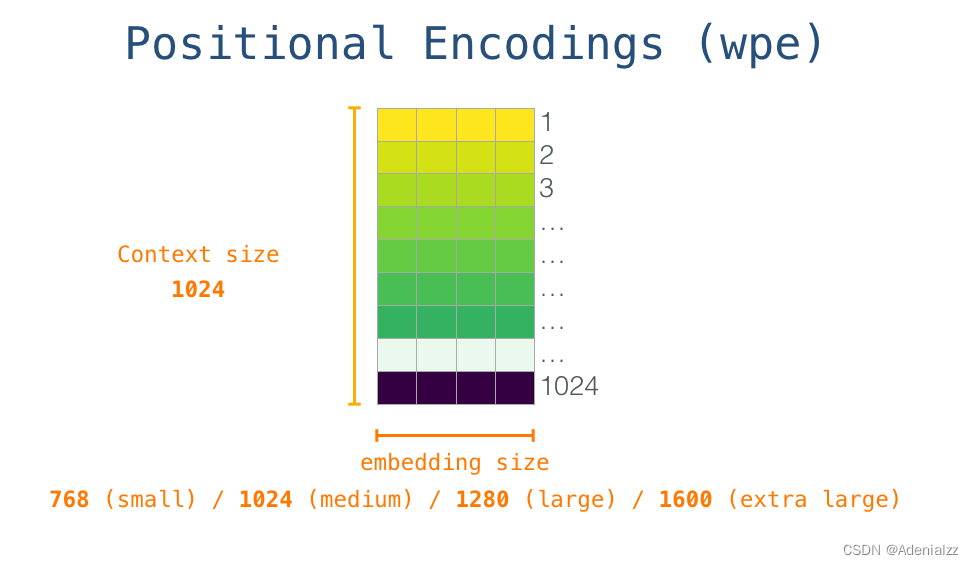
至此,輸入單詞在進(jìn)入模型第一個(gè) transformer 模塊之前所有的處理步驟就結(jié)束了����。如上文所述�����,訓(xùn)練后的 GPT-2 模型包含兩個(gè)權(quán)值矩陣:嵌入矩陣和位置編碼矩陣�。

將單詞輸入第一個(gè) transformer 模塊之前需要查到它對(duì)應(yīng)的嵌入向量����,再加上 1 號(hào)位置位置對(duì)應(yīng)的位置向量。
堆棧之旅
第一個(gè) transformer 模塊處理單詞的步驟如下:首先通過自注意力層處理�����,接著將其傳遞給神經(jīng)網(wǎng)絡(luò)層。第一個(gè) transformer 模塊處理完但此后���,會(huì)將結(jié)果向量被傳入堆棧中的下一個(gè) transformer 模塊��,繼續(xù)進(jìn)行計(jì)算。每一個(gè) transformer 模塊的處理方式都是一樣的���,但每個(gè)模塊都會(huì)維護(hù)自己的自注意力層和神經(jīng)網(wǎng)絡(luò)層中的權(quán)重�。
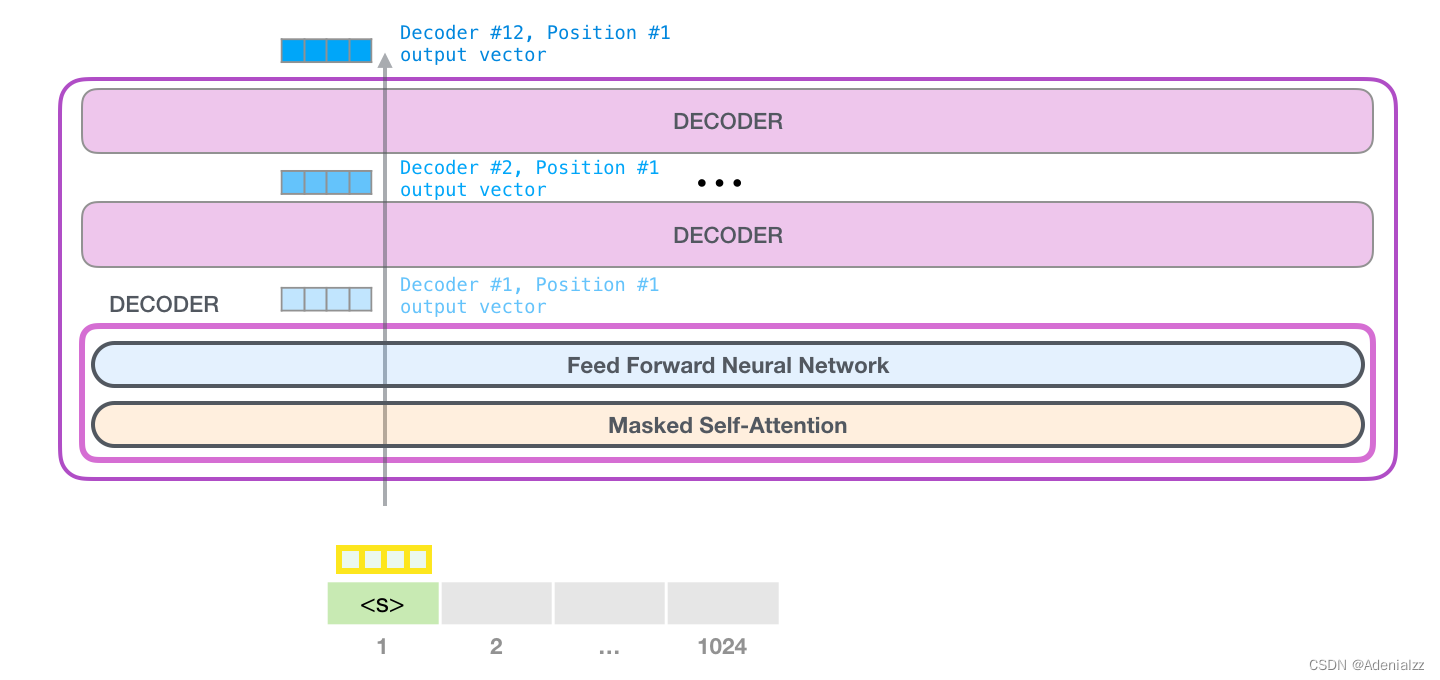
回顧自注意力機(jī)制
語言的含義是極度依賴上下文的,比如下面這個(gè)機(jī)器人第二法則:
Second Law of Robotics
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
機(jī)器人第二法則
機(jī)器人必須遵守人類給它的命令,除非該命令違背了第一法則����。
我在這句話中高亮表示了三個(gè)地方�����,這三處單詞指代的是其它單詞。除非我們知道這些詞指代的上下文聯(lián)系起來��,否則根本不可能理解或處理這些詞語的意思。當(dāng)模型處理這句話的時(shí)候���,它必須知道:
這就是自注意力機(jī)制所做的工作,它在處理每個(gè)單詞(將其傳入神經(jīng)網(wǎng)絡(luò))之前���,融入了模型對(duì)于用來解釋某個(gè)單詞的上下文的相關(guān)單詞的理解。具體做法是,給序列中每一個(gè)單詞都賦予一個(gè)相關(guān)度得分�����,之后對(duì)他們的向量表征求和。
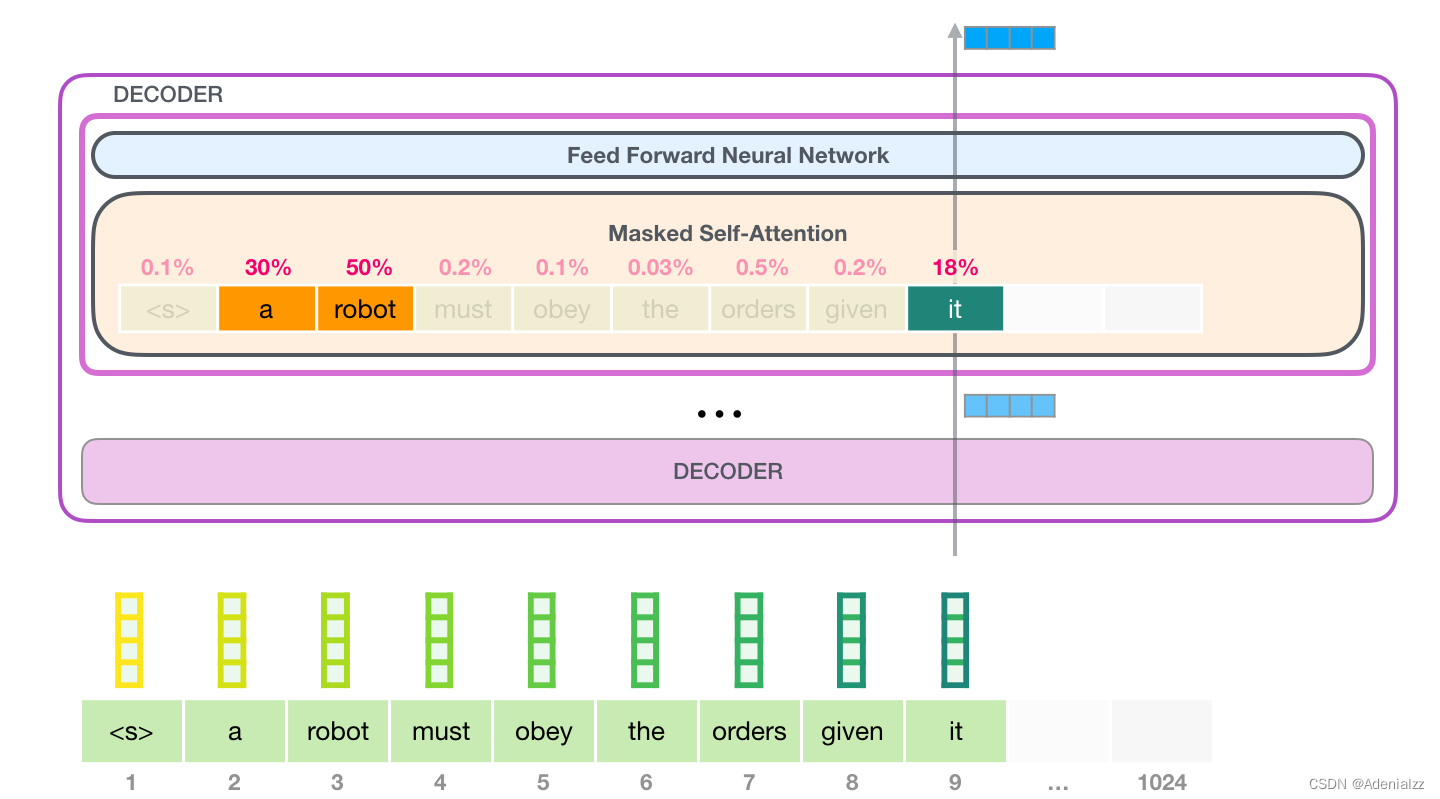
舉個(gè)例子����,最上層的 transformer 模塊在處理單詞「it」的時(shí)候會(huì)關(guān)注「a robot」����,所以「a」��、「robot」��、「it」這三個(gè)單詞與其得分相乘加權(quán)求和后的特征向量會(huì)被送入之后的神經(jīng)網(wǎng)絡(luò)層����。
自注意力機(jī)制沿著序列中每一個(gè)單詞的路徑進(jìn)行處理�,主要由 3 個(gè)向量組成:
查詢向量(Query 向量):當(dāng)前單詞的查詢向量被用來和其它單詞的鍵向量相乘,從而得到其它詞相對(duì)于當(dāng)前詞的注意力得分��。我們只關(guān)心目前正在處理的單詞的查詢向量。
鍵向量(Key 向量):鍵向量就像是序列中每個(gè)單詞的標(biāo)簽,它使我們搜索相關(guān)單詞時(shí)用來匹配的對(duì)象�����。
值向量(Value 向量):值向量是單詞真正的表征,當(dāng)我們算出注意力得分后�����,使用值向量進(jìn)行加權(quán)求和得到能代表當(dāng)前位置上下文的向量。
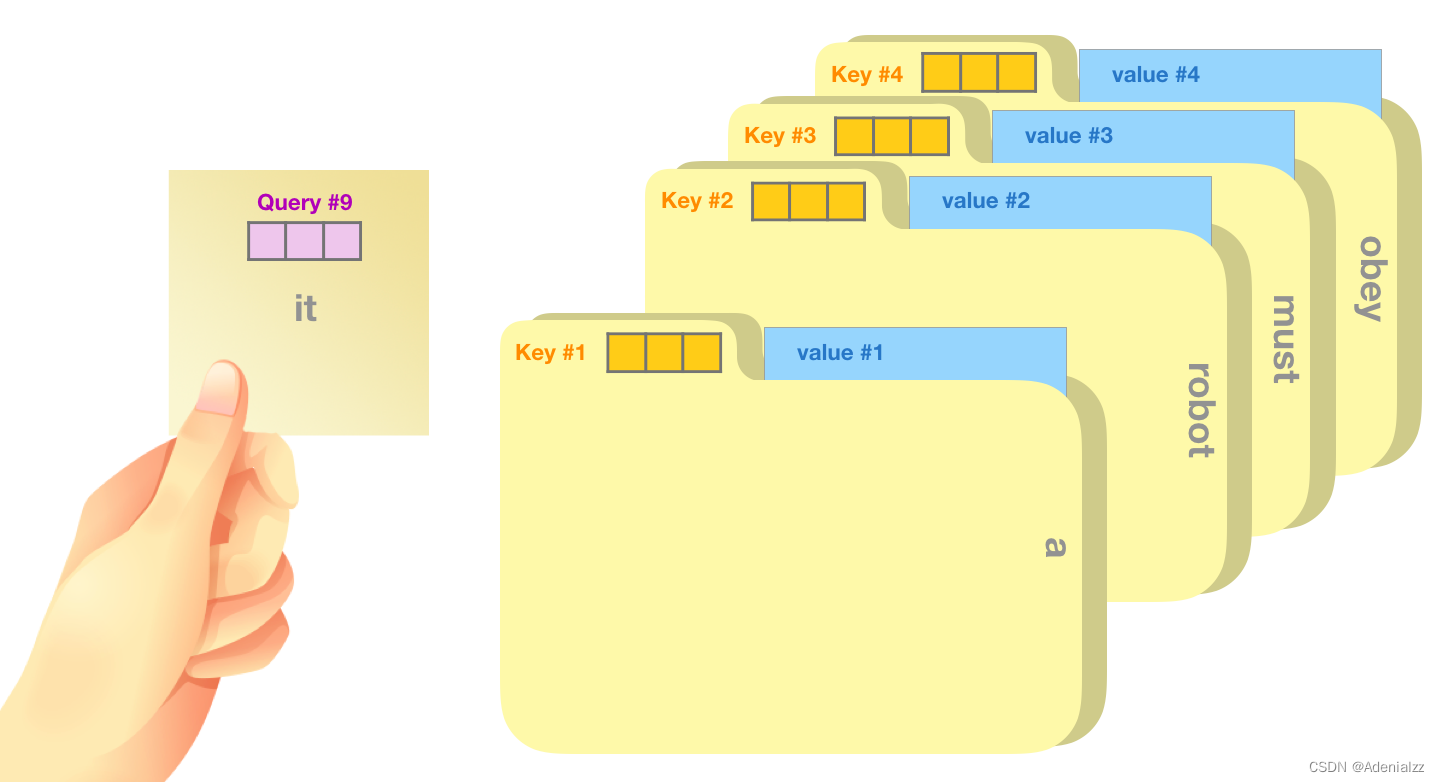
一個(gè)簡(jiǎn)單粗暴的比喻是在檔案柜中找文件��。查詢向量就像一張便利貼,上面寫著你正在研究的課題��。鍵向量像是檔案柜中文件夾上貼的標(biāo)簽��。當(dāng)你找到和便利貼上所寫相匹配的文件夾時(shí)�,拿出它���,文件夾里的東西便是值向量�����。只不過我們最后找的并不是單一的值向量,而是很多文件夾值向量的混合����。
將單詞的查詢向量分別乘以每個(gè)文件夾的鍵向量,得到各個(gè)文件夾對(duì)應(yīng)的注意力得分(這里的乘指的是向量點(diǎn)乘�,乘積會(huì)通過 softmax 函數(shù)處理)���。
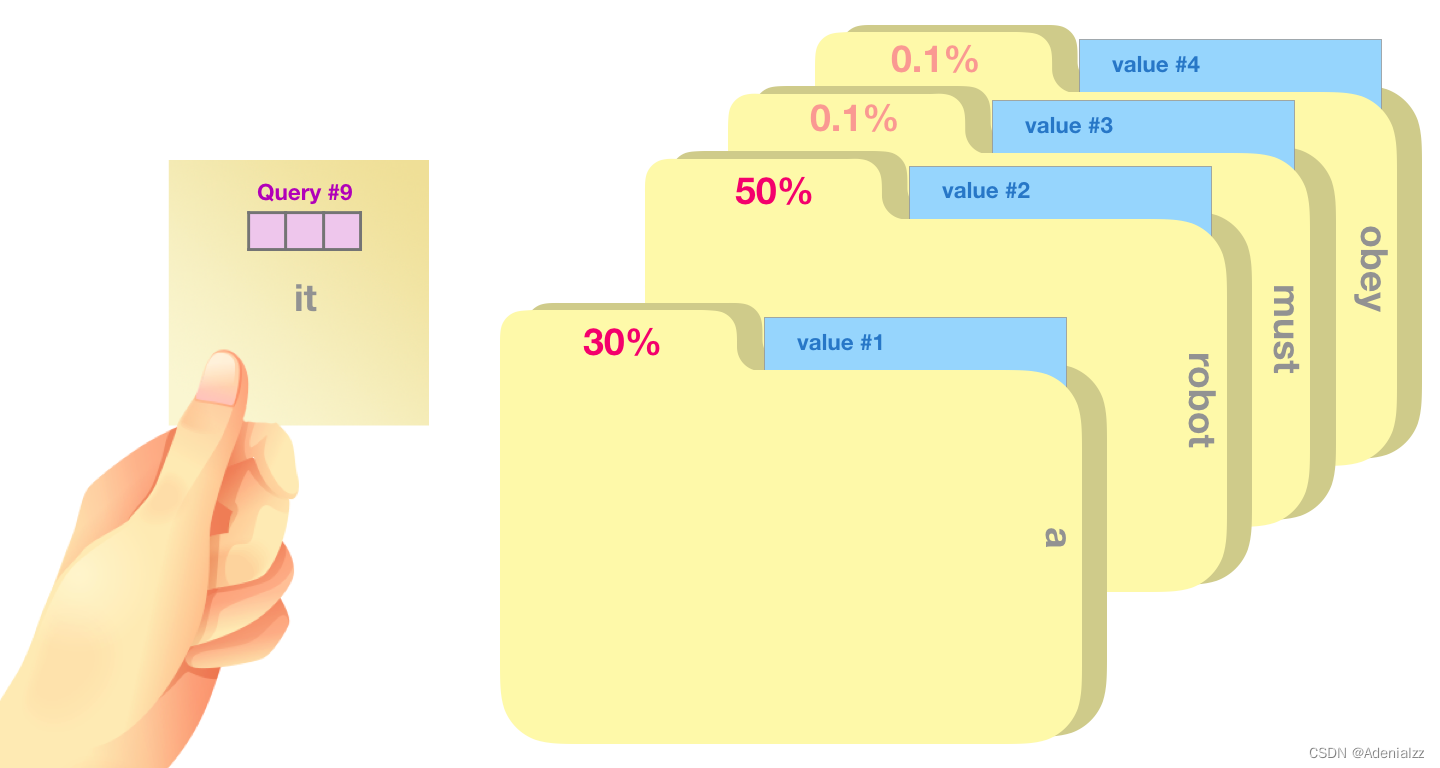
我們將每個(gè)文件夾的值向量乘以其對(duì)應(yīng)的注意力得分���,然后求和��,得到最終自注意力層的輸出��。
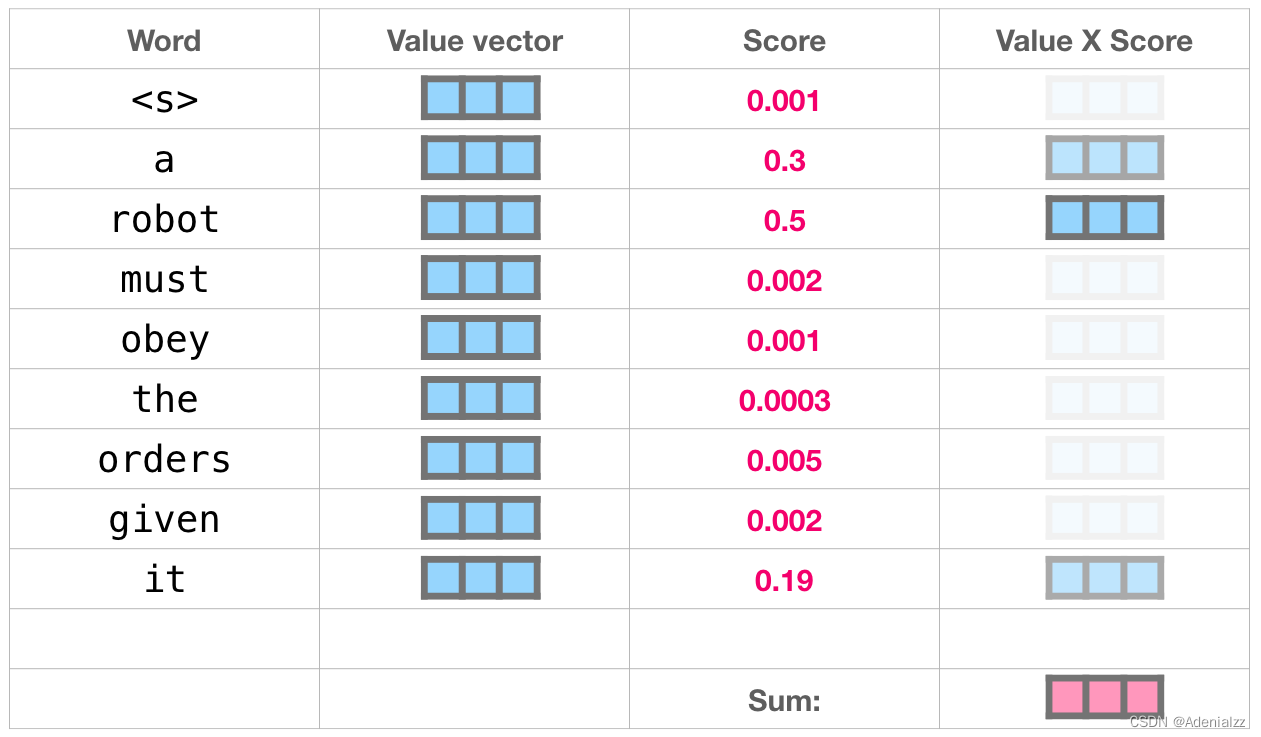
這樣將值向量加權(quán)混合得到的結(jié)果是一個(gè)向量,它將其 50% 的「注意力」放在了單詞「robot」上��,30% 的注意力放在了「a」上,還有 19% 的注意力放在「it」上�。我們之后還會(huì)更詳細(xì)地講解自注意力機(jī)制�����,讓我們先繼續(xù)向前探索 transformer 堆棧�����,看看模型的輸出。
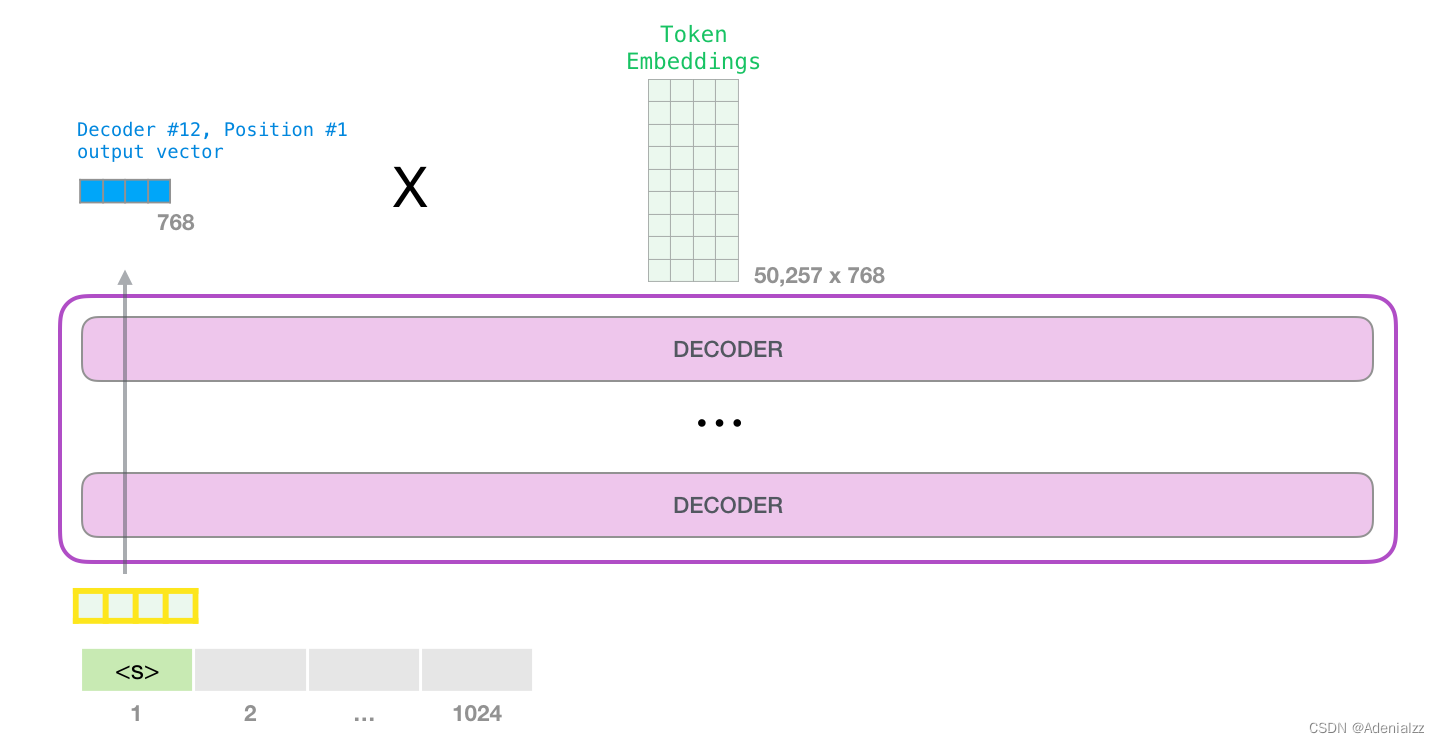
模型輸出
當(dāng)最后一個(gè) transformer 模塊產(chǎn)生輸出之后(即經(jīng)過了它自注意力層和神經(jīng)網(wǎng)絡(luò)層的處理),模型會(huì)將輸出的向量乘上嵌入矩陣����。
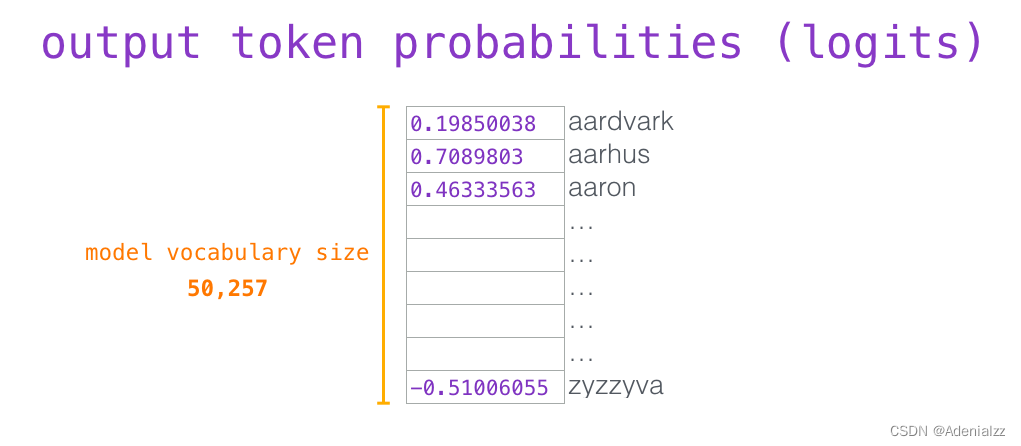
我們知道���,嵌入矩陣的每一行都對(duì)應(yīng)模型的詞匯表中一個(gè)單詞的嵌入向量�����。所以這個(gè)乘法操作得到的結(jié)果就是詞匯表中每個(gè)單詞對(duì)應(yīng)的注意力得分�。
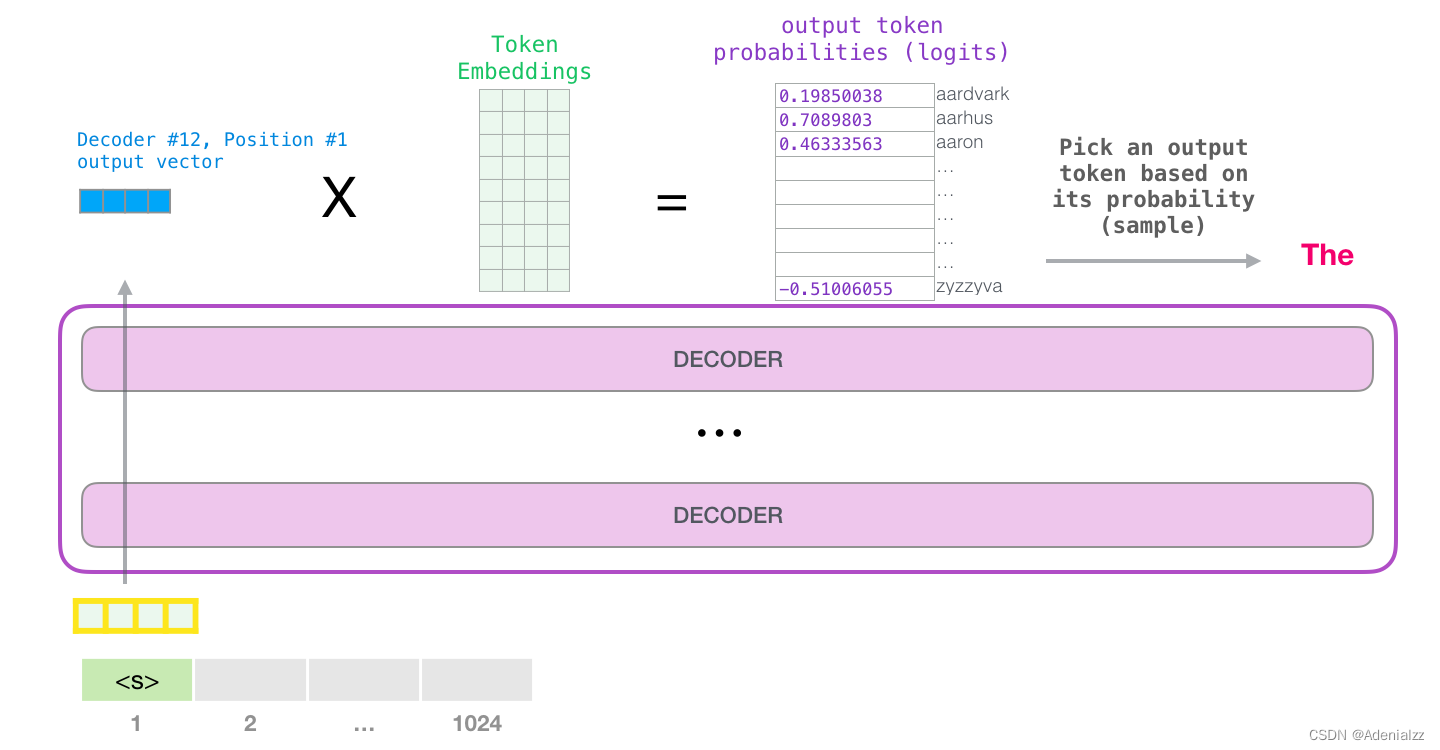
我們簡(jiǎn)單地選取得分最高的單詞作為輸出結(jié)果(即 top-k = 1)����。但其實(shí)如果模型考慮其他候選單詞的話���,效果通常會(huì)更好�。所以���,一個(gè)更好的策略是對(duì)于詞匯表中得分較高的一部分單詞�����,將它們的得分作為概率從整個(gè)單詞列表中進(jìn)行抽樣(得分越高的單詞越容易被選中)���。通常一個(gè)折中的方法是���,將 top-k 設(shè)為 40,這樣模型會(huì)考慮注意力得分排名前 40 位的單詞�。
這樣���,模型就完成了一輪迭代���,輸出了一個(gè)單詞����。模型會(huì)接著不斷迭代,直到生成一個(gè)完整的序列——序列達(dá)到 1024 的長(zhǎng)度上限或序列中產(chǎn)生了一個(gè)終止符。
第一部分結(jié)語:大家好�����,這就是 GPT-2
本文是 GPT-2 模型工作原理的一個(gè)概覽����。如果你還是對(duì)自注意力層內(nèi)部深層的細(xì)節(jié)很好奇���,請(qǐng)繼續(xù)關(guān)注機(jī)器之心的系列文章��。我們將引入更多可視化語言來試著解釋自注意力層的工作原理�,同時(shí)也是為了能夠更好地描述之后基于 transformer 的模型(說的就是你們�,TransformerXL 還有 XLNet)�。
這篇文章中有一些過分簡(jiǎn)化的地方:
混用了「單詞」(word)和「詞」(token)這兩個(gè)概念�。但事實(shí)上�����,GPT-2 使用字節(jié)對(duì)編碼(Byte Pair Encoding)方式來創(chuàng)建詞匯表中的詞(token)�,也就是說詞(token)其實(shí)通常只是單詞的一部分。
舉的例子其實(shí)是 GPT-2 在「推斷/評(píng)價(jià)」(inference / evaluation)模式下運(yùn)行的流程,所以一次只處理一個(gè)單詞���。在訓(xùn)練過程中�,模型會(huì)在更長(zhǎng)的文本序列上進(jìn)行訓(xùn)練����,并且一次處理多個(gè)詞(token)。訓(xùn)練過程的批處理大?��。╞atch size)也更大(512)��,而評(píng)價(jià)時(shí)的批處理大小只有 1��。
為了更好地組織空間中的圖像,作者畫圖時(shí)隨意轉(zhuǎn)置了向量���,但在實(shí)現(xiàn)時(shí)需要更精確�����。
Transformer 模塊使用了很多歸一化(normalization)層,這在訓(xùn)練中是很關(guān)鍵的�。我們?cè)?nbsp;The Illustrated Transformer 中提到了其中一些�����,但本文更關(guān)注自注意力層。
有時(shí)文章需要用更多的小方塊來代表一個(gè)向量��,我把這些情況叫做「放大」,如下圖所示�����。
第二部分:圖解自注意力機(jī)制
在前面的文章中,我們用這張圖來展示了自注意力機(jī)制在處理單詞「it」的層中的應(yīng)用:

在本節(jié)中,我們會(huì)詳細(xì)介紹該過程是如何實(shí)現(xiàn)的�。請(qǐng)注意�,我們將會(huì)以試圖弄清單個(gè)單詞被如何處理的角度來看待這個(gè)問題���。這也是我們會(huì)展示許多單個(gè)向量的原因。這實(shí)際上是通過將巨型矩陣相乘來實(shí)現(xiàn)的�。但是我想直觀地看看,在單詞層面上發(fā)生了什么。
自注意力機(jī)制(不使用掩模)
首先��,我們將介紹原始的自注意力機(jī)制,它是在編碼器模塊里計(jì)算的�。先看一個(gè)簡(jiǎn)易的 transformer 模塊��,它一次只能處理 4 個(gè)詞(token)��。
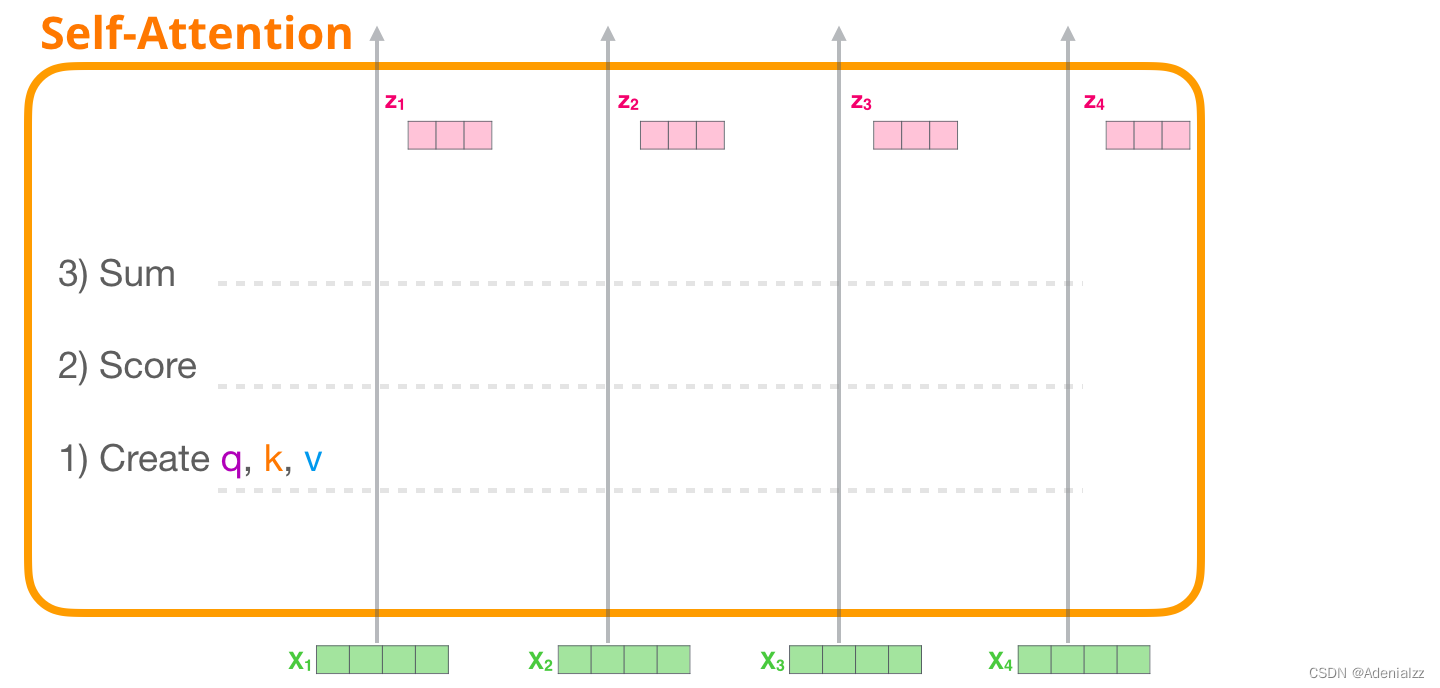
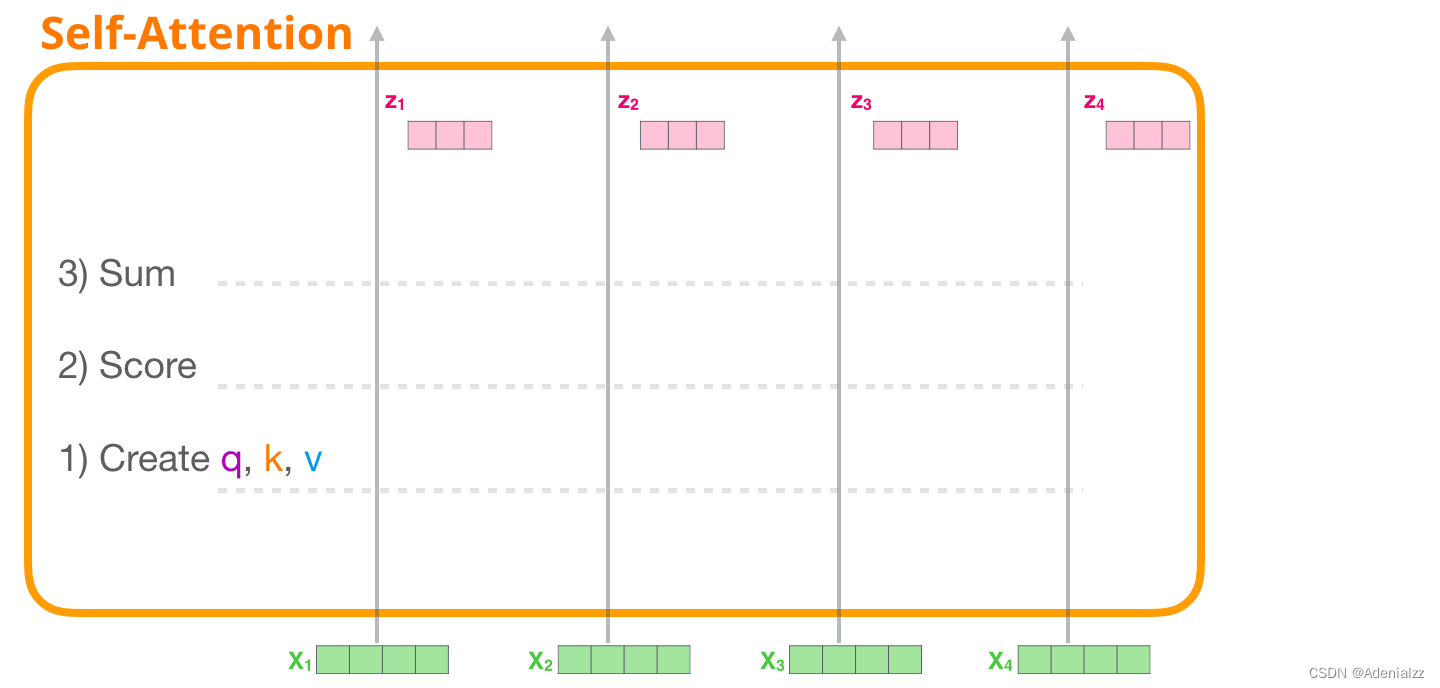
自注意力機(jī)制通過以下三個(gè)主要步驟來實(shí)現(xiàn):
為每個(gè)路徑創(chuàng)建查詢��、鍵和值向量。
對(duì)于每個(gè)輸入的詞��,通過使用其查詢向量與其它所有鍵向量相乘得到注意力得分。
將值向量與它們相應(yīng)的注意力得分相乘后求和
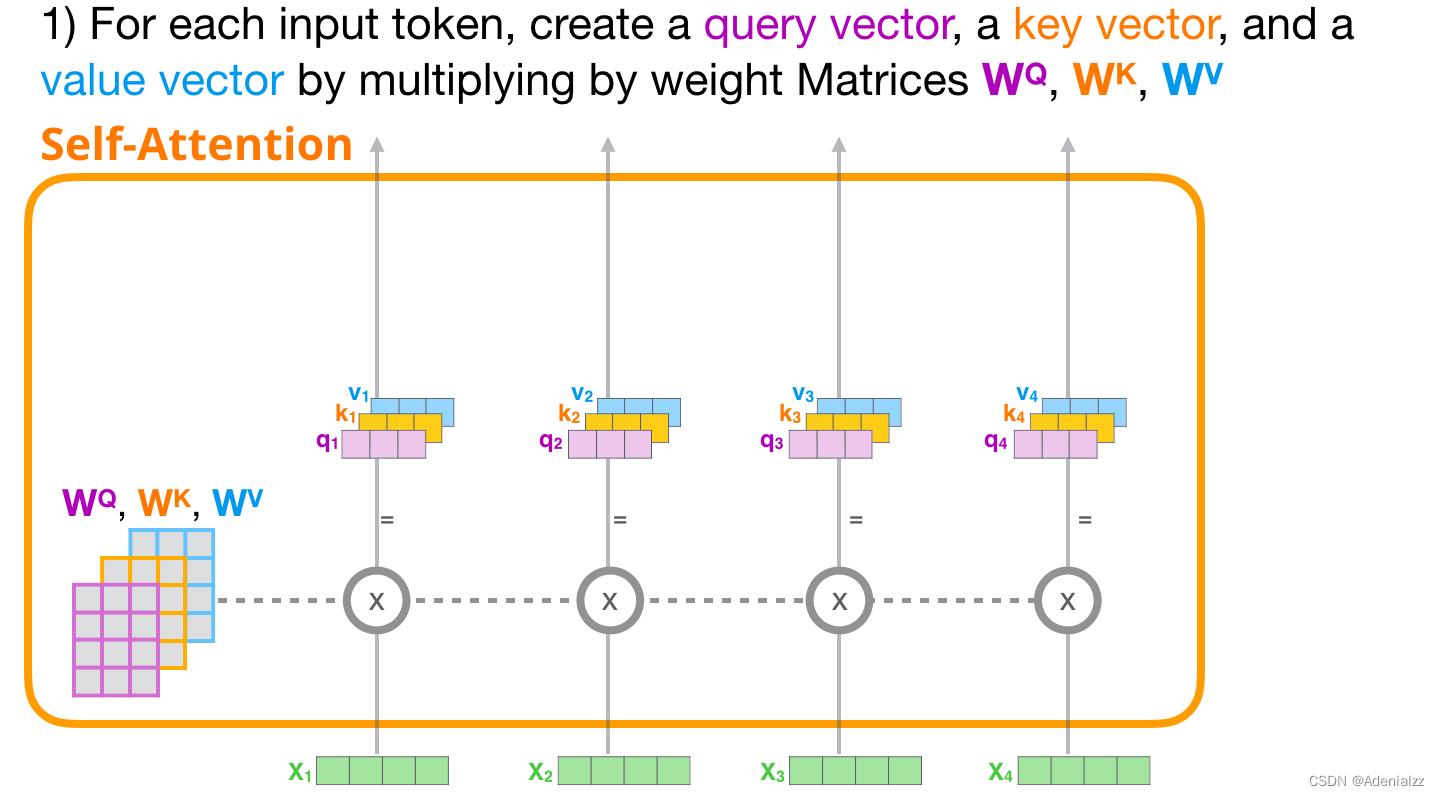
1 創(chuàng)建查詢����、鍵和值向量
我們重點(diǎn)關(guān)注第一條路徑���。我們用它的查詢值與其它所有的鍵向量進(jìn)行比較���,這使得每個(gè)鍵向量都有一個(gè)對(duì)應(yīng)的注意力得分。自注意力機(jī)制的第一步就是為每個(gè)詞(token)路徑(我們暫且忽略注意力頭)計(jì)算三個(gè)向量:查詢向量����、鍵向量�����、值向量。
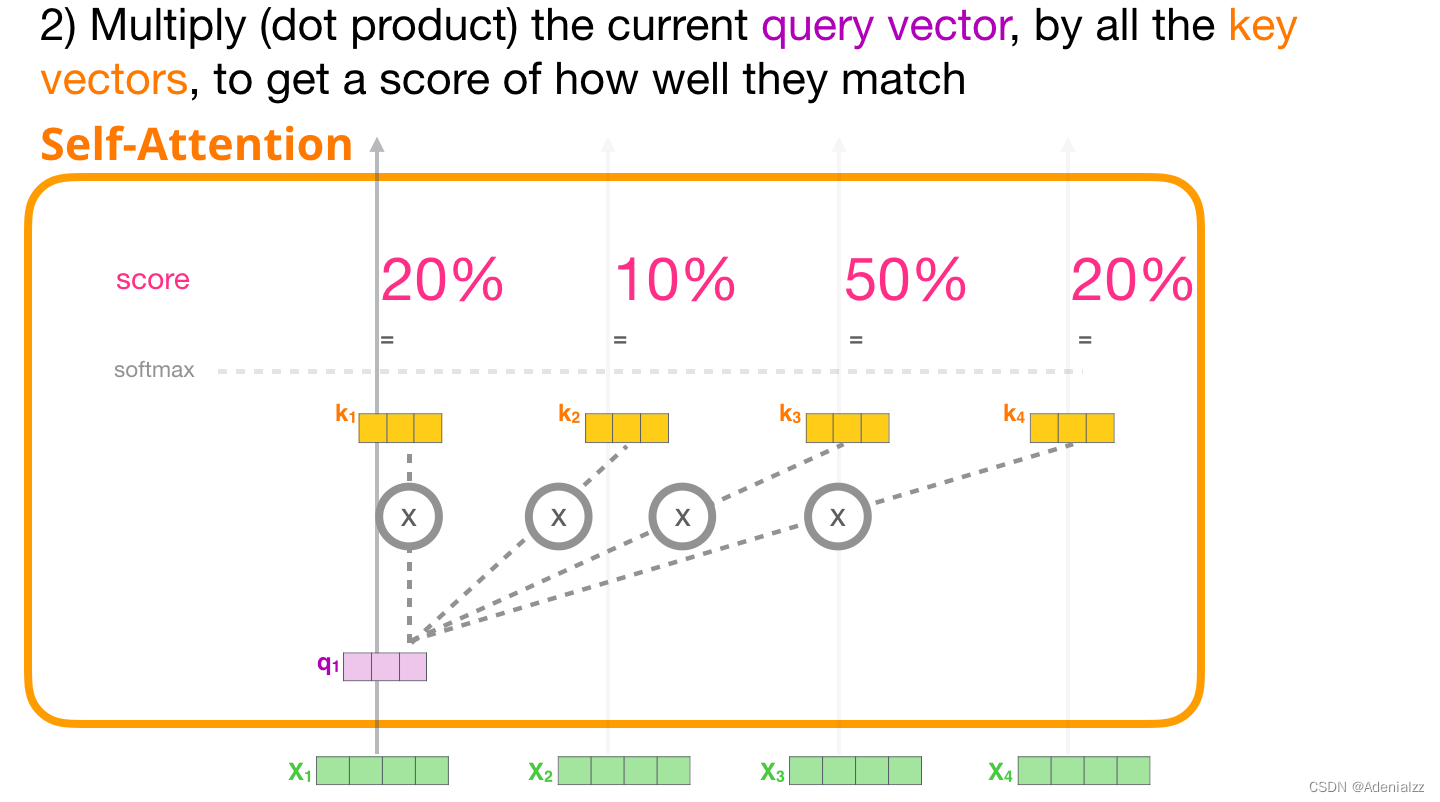
2 注意力得分
計(jì)算出上述三個(gè)向量后,我們?cè)诘诙街兄挥貌樵兿蛄亢玩I向量�����。我們重點(diǎn)關(guān)注第一個(gè)詞��,將它的查詢向量與其它所有的鍵向量相乘�,得到四個(gè)詞中的每個(gè)詞的注意力得分���。
3 求和
現(xiàn)在,我們可以將注意力得分與值向量相乘��。在我們對(duì)其求和后�����,注意力得分較高的值將在結(jié)果向量中占很大的比重。
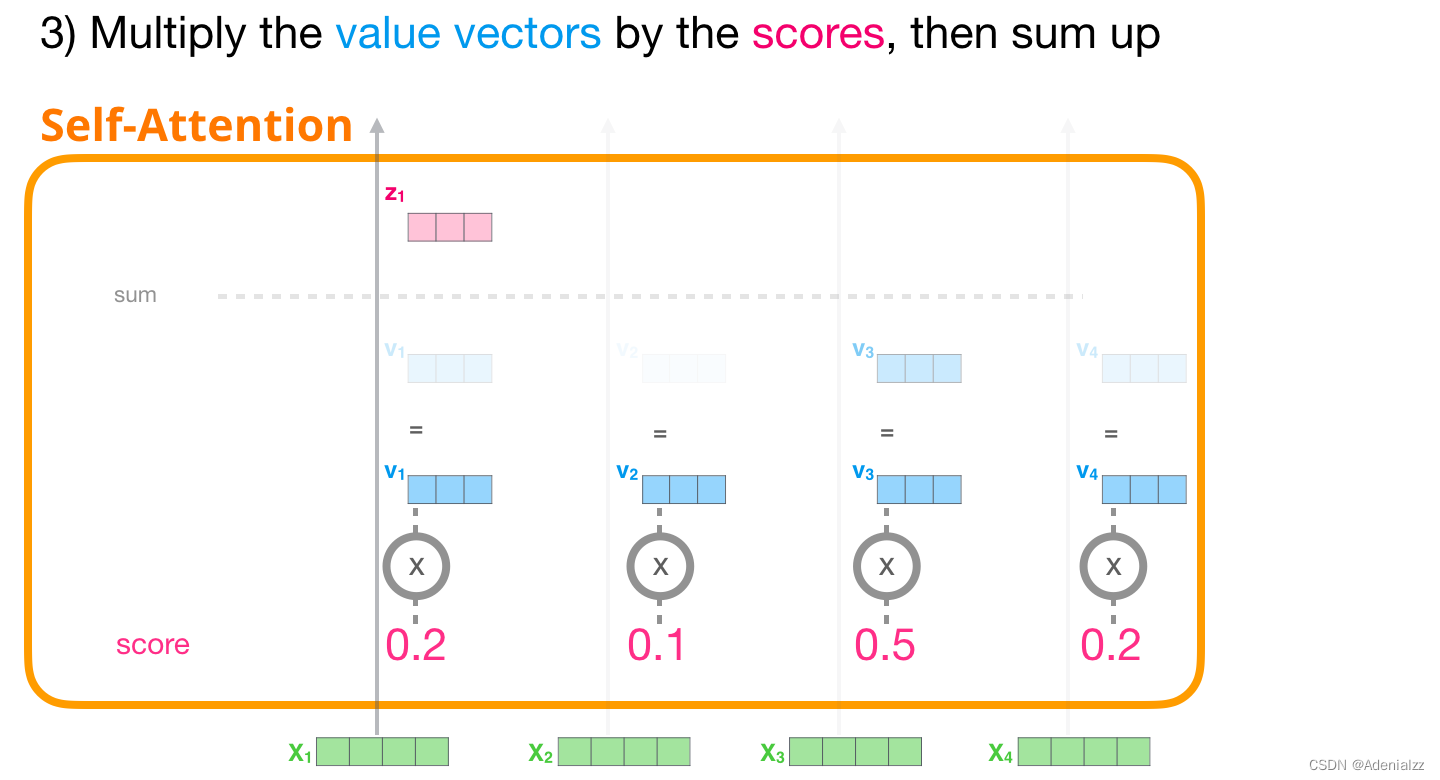
注意力得分越低,我們?cè)趫D中顯示的值向量就越透明���。這是為了表明乘以一個(gè)小的數(shù)是如何削弱向量值的影響的�����。
如果我們?cè)诿恳粋€(gè)路徑都執(zhí)行相同的操作��,最終會(huì)得到一個(gè)表征每個(gè)詞的向量�����,它包括了這個(gè)詞的適當(dāng)?shù)纳舷挛模缓髮⑦@些信息在 transformer 模塊中傳遞給下一個(gè)子層(前饋神經(jīng)網(wǎng)絡(luò)):
圖解掩模自注意力機(jī)制
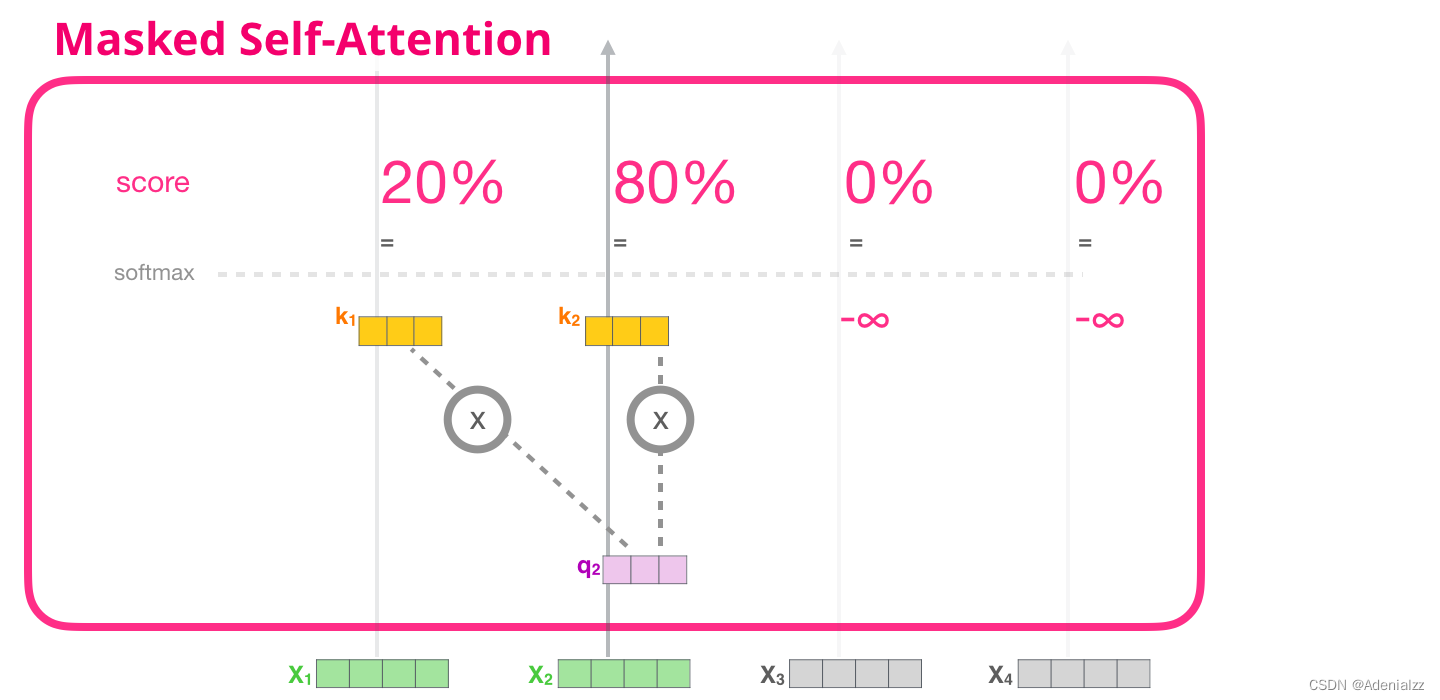
現(xiàn)在我們已經(jīng)介紹了 transformer 模塊中自注意力機(jī)制的步驟,接下來我們介紹掩模自注意力機(jī)制(masked self-attention)��。在掩模自注意力機(jī)制中����,除了第二步,其余部分與自注意力機(jī)制相同�。假設(shè)模型輸入只包含兩個(gè)詞��,我們正在觀察第二個(gè)詞�����。在這種情況下��,后兩個(gè)詞都被屏蔽了。因此模型會(huì)干擾計(jì)算注意力得分的步驟���。基本上����,它總是為序列中后續(xù)的詞賦予 0 分的注意力得分����,因此模型不會(huì)在后續(xù)單詞上得到最高的注意力得分:
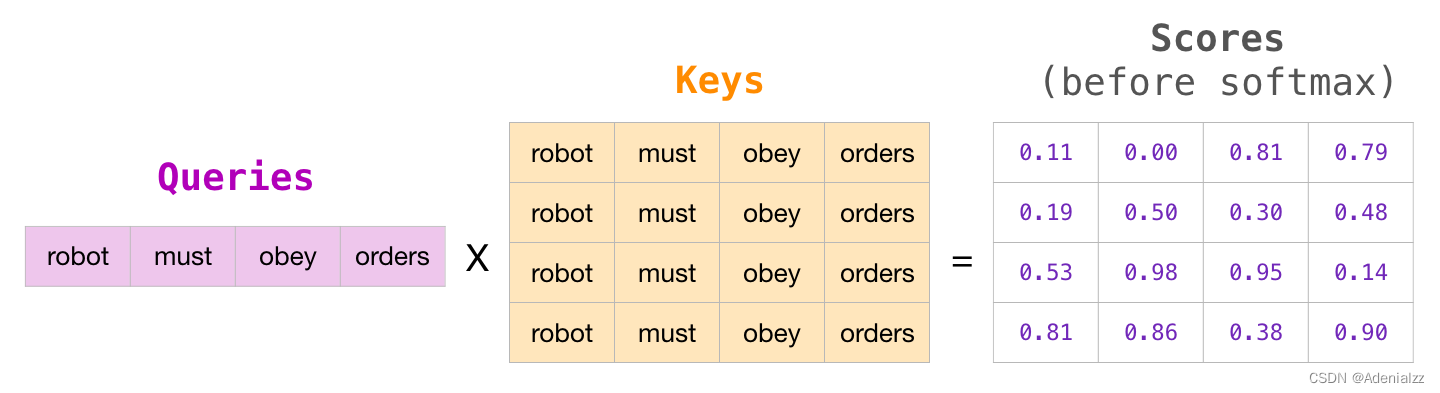
我們通常使用注意力掩模矩陣來實(shí)現(xiàn)這種屏蔽操作����。不妨想象一個(gè)由四個(gè)單詞組成的序列(例如「robot must obey orders」(機(jī)器人必須服從命令))在語言建模場(chǎng)景中�����,這個(gè)序列被分成四步進(jìn)行處理——每個(gè)單詞一步(假設(shè)現(xiàn)在每個(gè)單詞(word)都是一個(gè)詞(token))��。由于這些模型都是批量執(zhí)行的��,我們假設(shè)這個(gè)小型模型的批處理大小為 4��,它將整個(gè)序列(包含 4 步)作為一個(gè)批處理�。

在矩陣形式中����,我們通過將查詢矩陣和鍵矩陣相乘來計(jì)算注意力得分�����。該過程的可視化結(jié)果如下所示�,下圖使用的是與單元格中該單詞相關(guān)聯(lián)的查詢(或鍵)向量�,而不是單詞本身:
在相乘之后��,我們加上注意力掩模三角矩陣����。它將我們想要屏蔽的單元格設(shè)置為負(fù)無窮或非常大的負(fù)數(shù)(例如�����,在 GPT2 中為 -10 億):

然后�����,對(duì)每一行執(zhí)行 softmax 操作�����,從而得到我們?cè)谧宰⒁饬C(jī)制中實(shí)際使用的注意力得分:

此分?jǐn)?shù)表的含義如下:
當(dāng)模型處理數(shù)據(jù)集中的第一個(gè)示例(第一行)時(shí)�����,這里只包含了一個(gè)單詞(「robot」)���,所以 100% 的注意力都在該單詞上。
當(dāng)模型處理數(shù)據(jù)集中的第二個(gè)示例(第二行)時(shí)�����,這里包含了(「robot must」),當(dāng)它處理單詞「must」時(shí)����,48% 的注意力會(huì)在「robot」上�,而另外 52% 的注意力會(huì)在「must」上���。
以此類推
GPT-2 的掩模自注意力機(jī)制
接下來����,我們將更詳細(xì)地分析 GPT-2 的掩模自注意力機(jī)制�����。
模型評(píng)價(jià)時(shí):一次只處理一個(gè)詞
我們可以通過掩模自注意機(jī)制的方式執(zhí)行 GPT-2�。但是在模型評(píng)價(jià)時(shí)�,當(dāng)我們的模型每輪迭代后只增加一個(gè)新單詞時(shí)��,沿著先前已經(jīng)處理過的路徑再重新計(jì)算詞(tokrn)的自注意力是效率極低的���。
在這種情況下�����,我們處理第一個(gè)詞(暫時(shí)忽略 <s> )
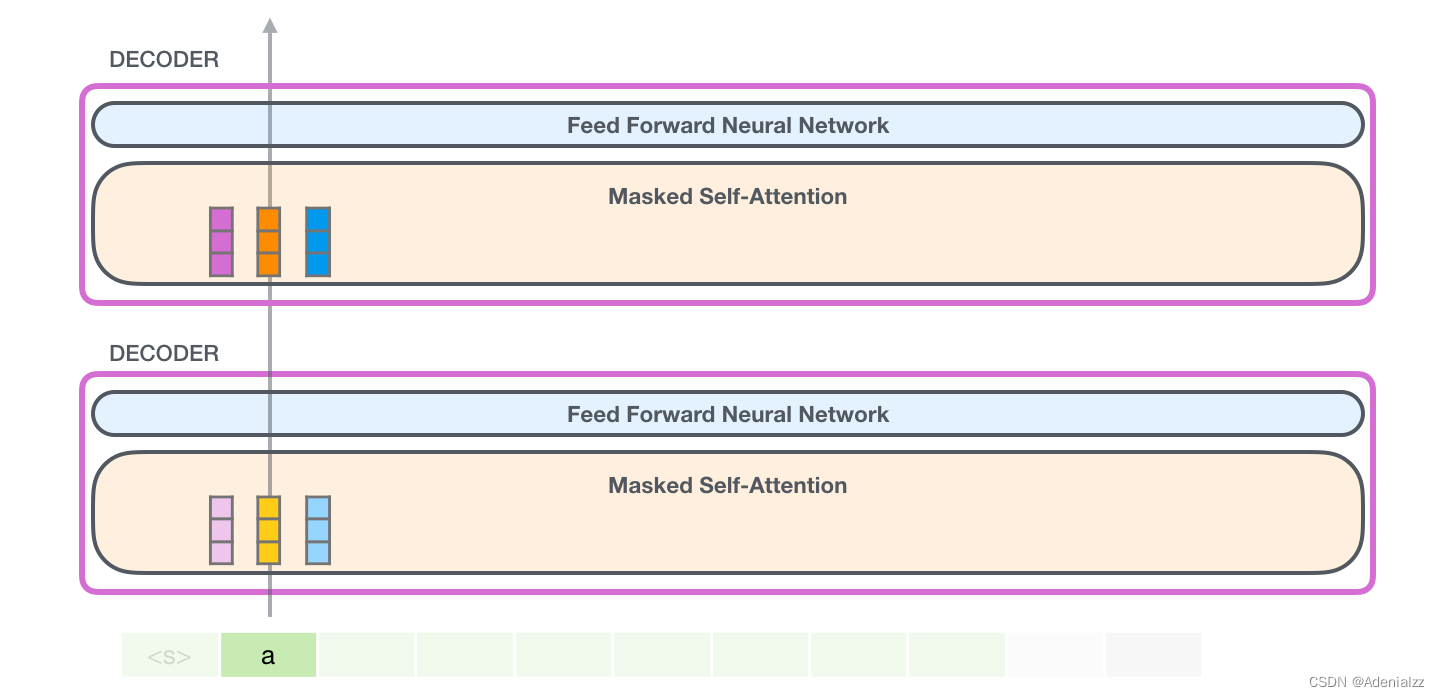
GPT-2 保存了詞「a」的鍵向量和值向量。每個(gè)自注意力層包括了該詞相應(yīng)的鍵和值向量�。
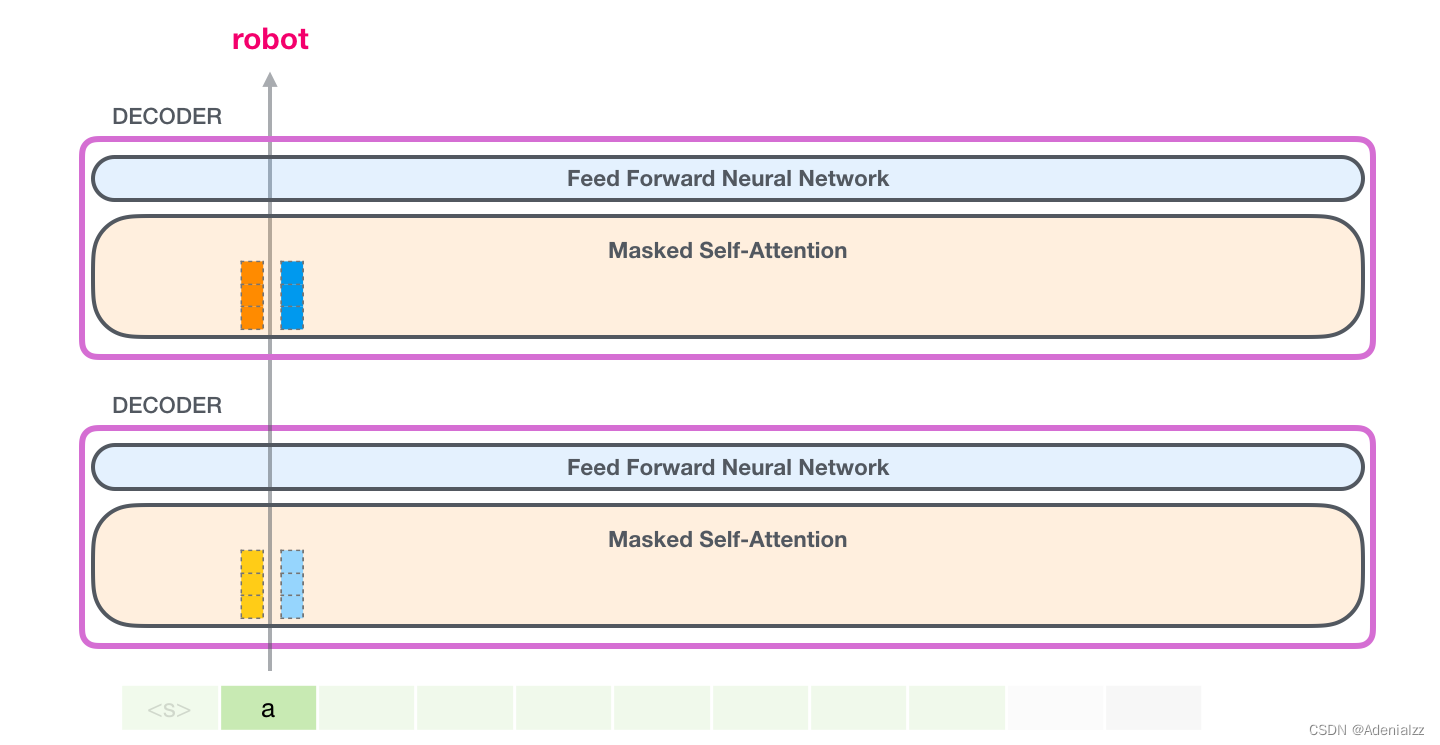
在下一次迭代中�,當(dāng)模型處理單詞「robot」時(shí)�����,它不再需要為詞「a」生成查詢�����、鍵和值向量����。它只需要復(fù)用第一次迭代中保存的向量:
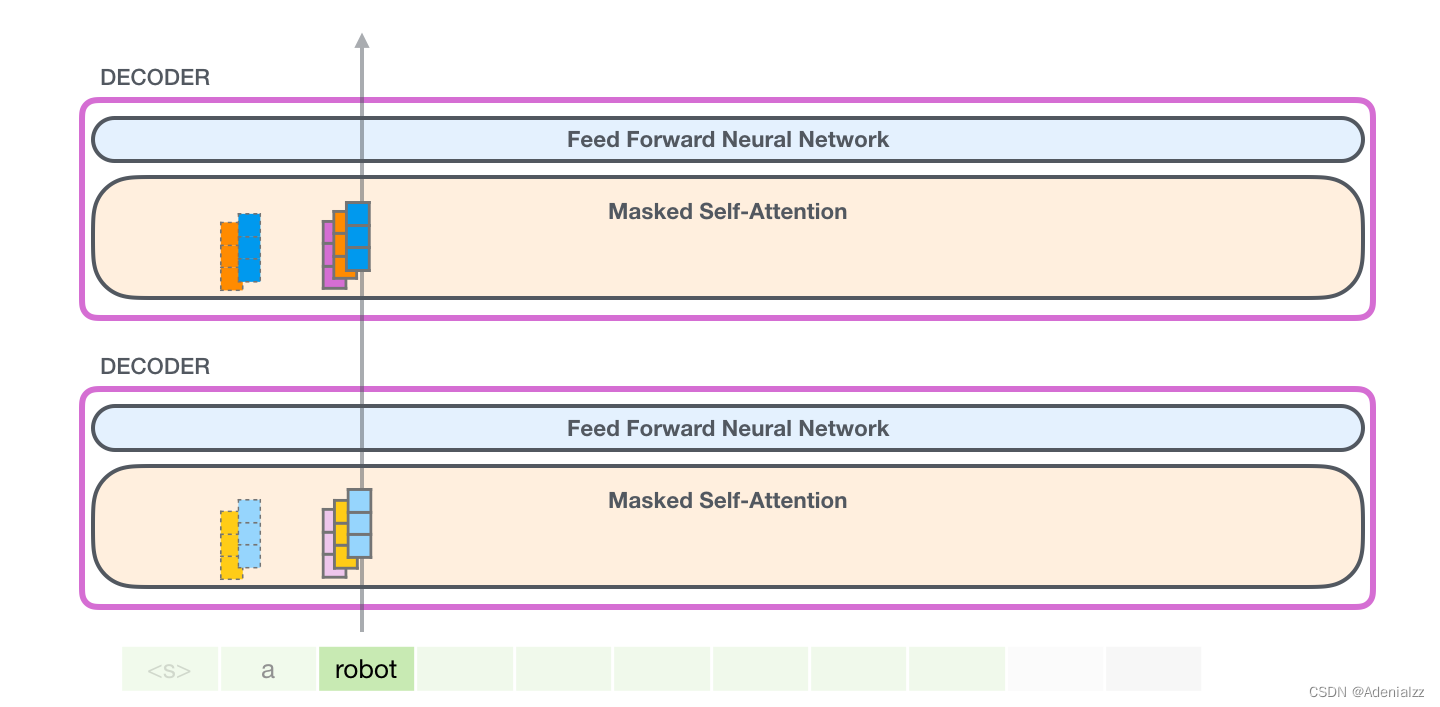
GPT-2 自注意力機(jī)制:1-創(chuàng)建查詢、鍵和值
假設(shè)模型正在處理單詞「it」���。對(duì)于下圖中底部的模塊來說�����,它對(duì)該詞的輸入則是「it」的嵌入向量+序列中第九個(gè)位置的位置編碼
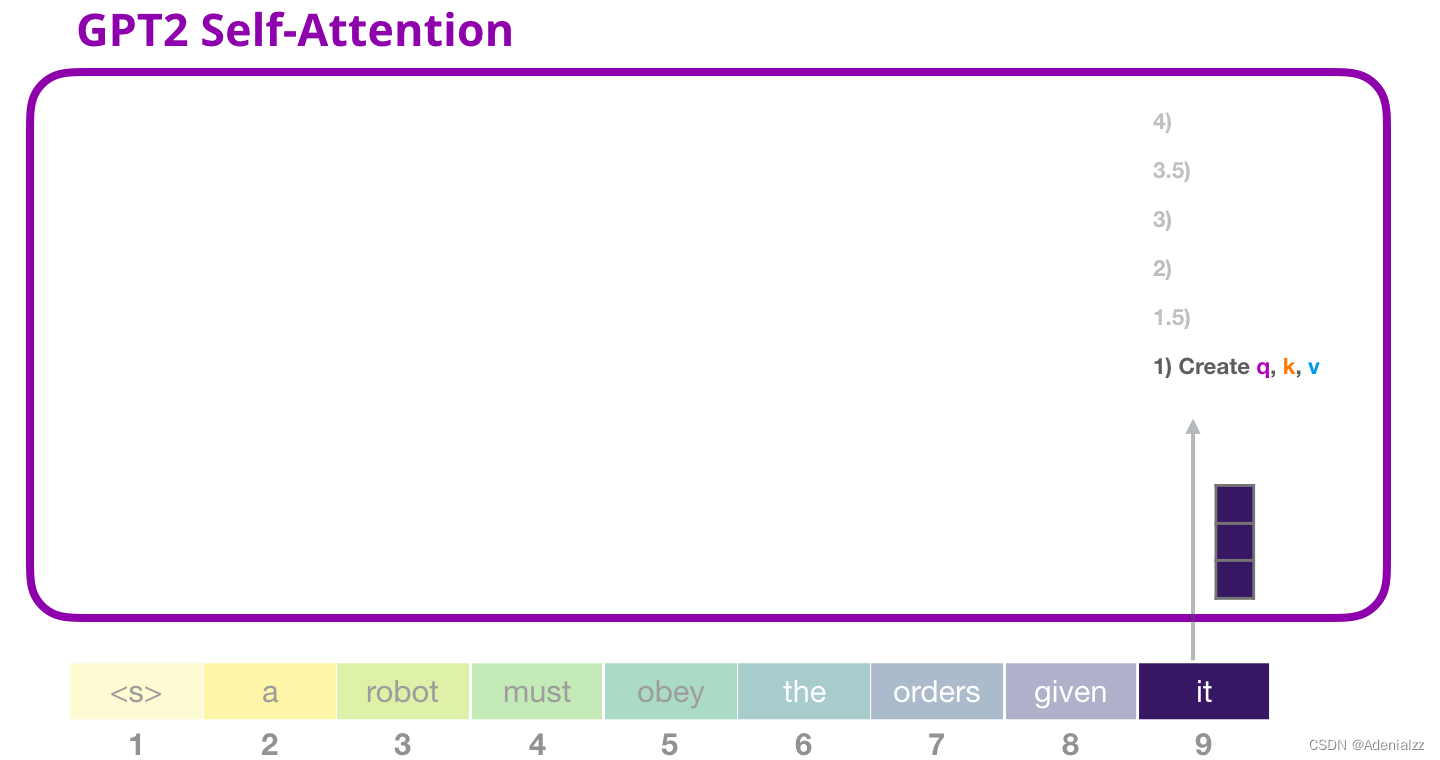
Transformer 中的每個(gè)模塊都有自己的權(quán)重(之后會(huì)詳細(xì)分析)�。我們首先看到的是用于創(chuàng)建查詢、鍵和值的權(quán)重矩陣��。
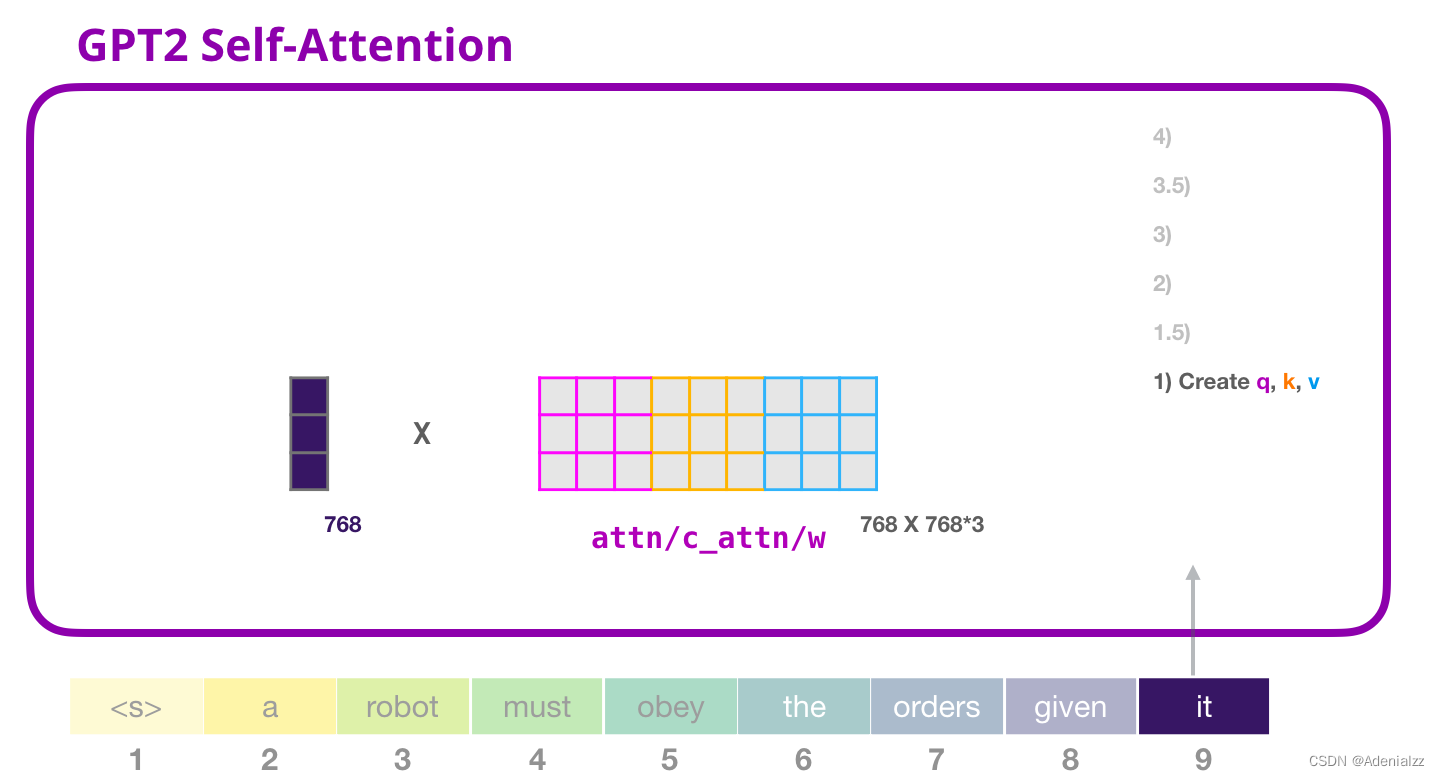
自注意力機(jī)制將它的輸入與權(quán)重矩陣相乘(并加上一個(gè)偏置向量���,這里不作圖示)。
相乘后得到的向量從基本就是單詞「it」的查詢�、鍵和值向量連接 的結(jié)果�。
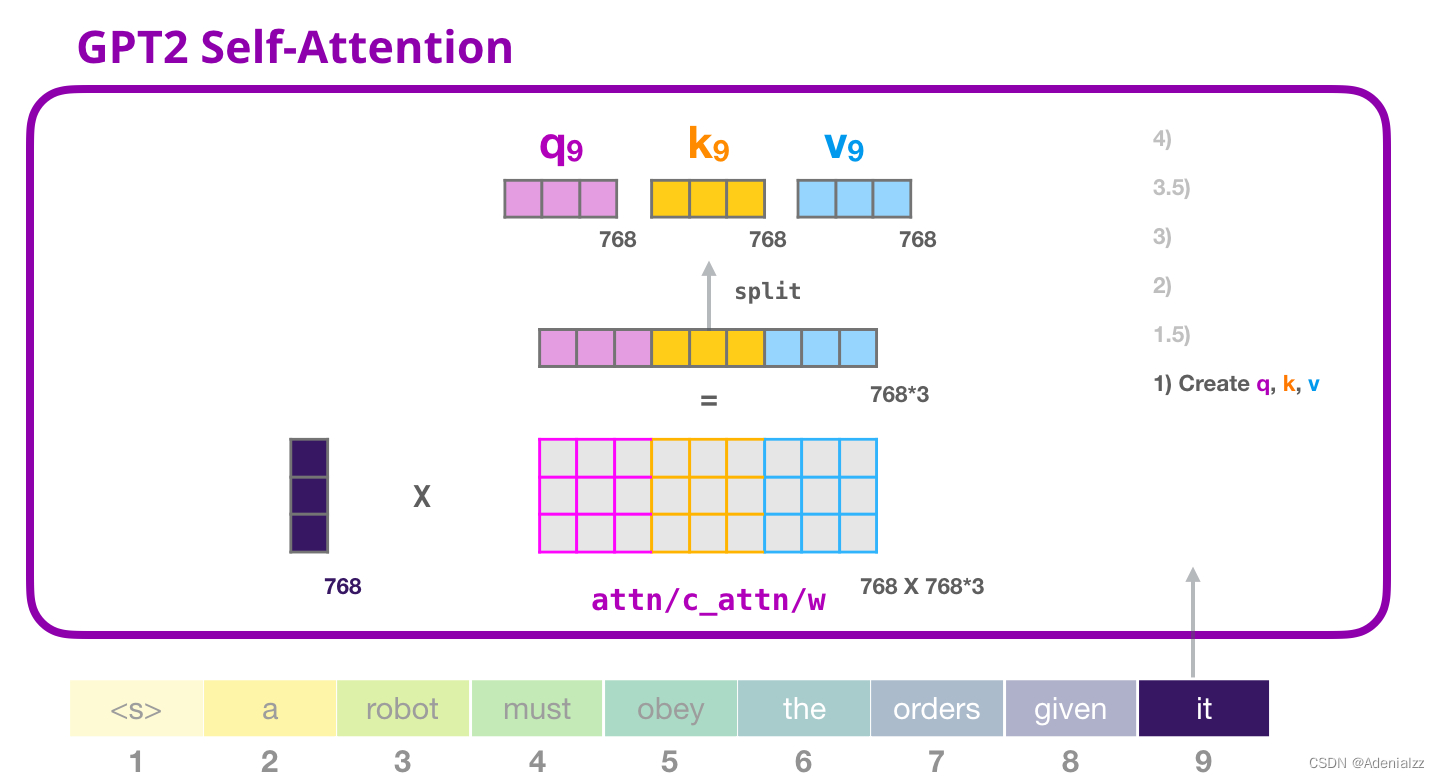
將輸入向量和注意力權(quán)重向量相乘(之后加上偏置向量)得到這個(gè)詞的鍵�����、值和查詢向量。
GPT-2 自注意力機(jī)制:1.5-分裂成注意力頭
在前面的示例中��,我們直接介紹了自注意力機(jī)制而忽略了「多頭」的部分。現(xiàn)在���,對(duì)這部分概念有所了解會(huì)大有用處。自注意力機(jī)制是在查詢(Q)�、鍵(K)�、值(V)向量的不同部分多次進(jìn)行的?��!阜至选棺⒁饬︻^指的是�����,簡(jiǎn)單地將長(zhǎng)向量重塑成矩陣形式。在小型的 GPT-2 中�����,有 12 個(gè)注意力頭���,因此這是重塑矩陣中的第一維:
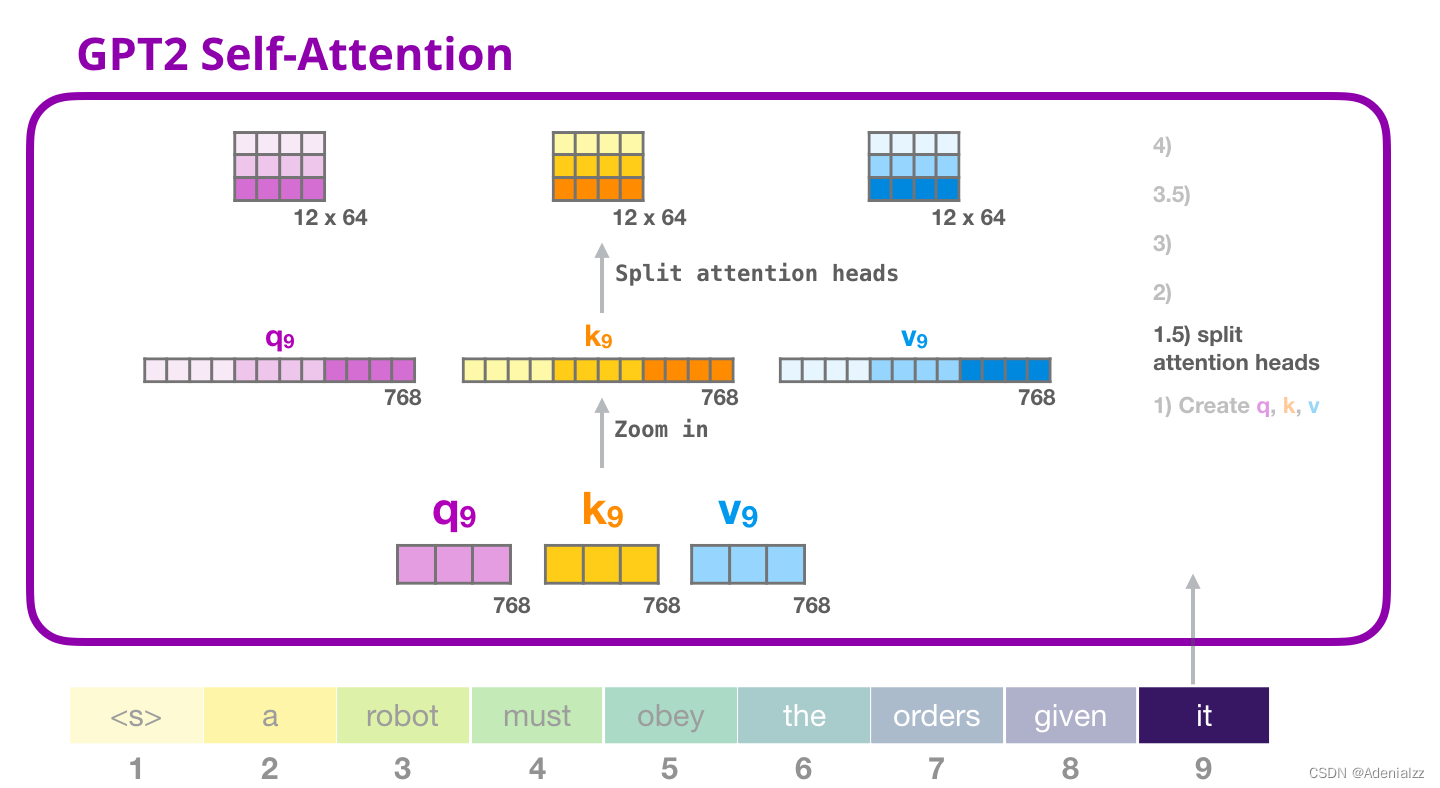
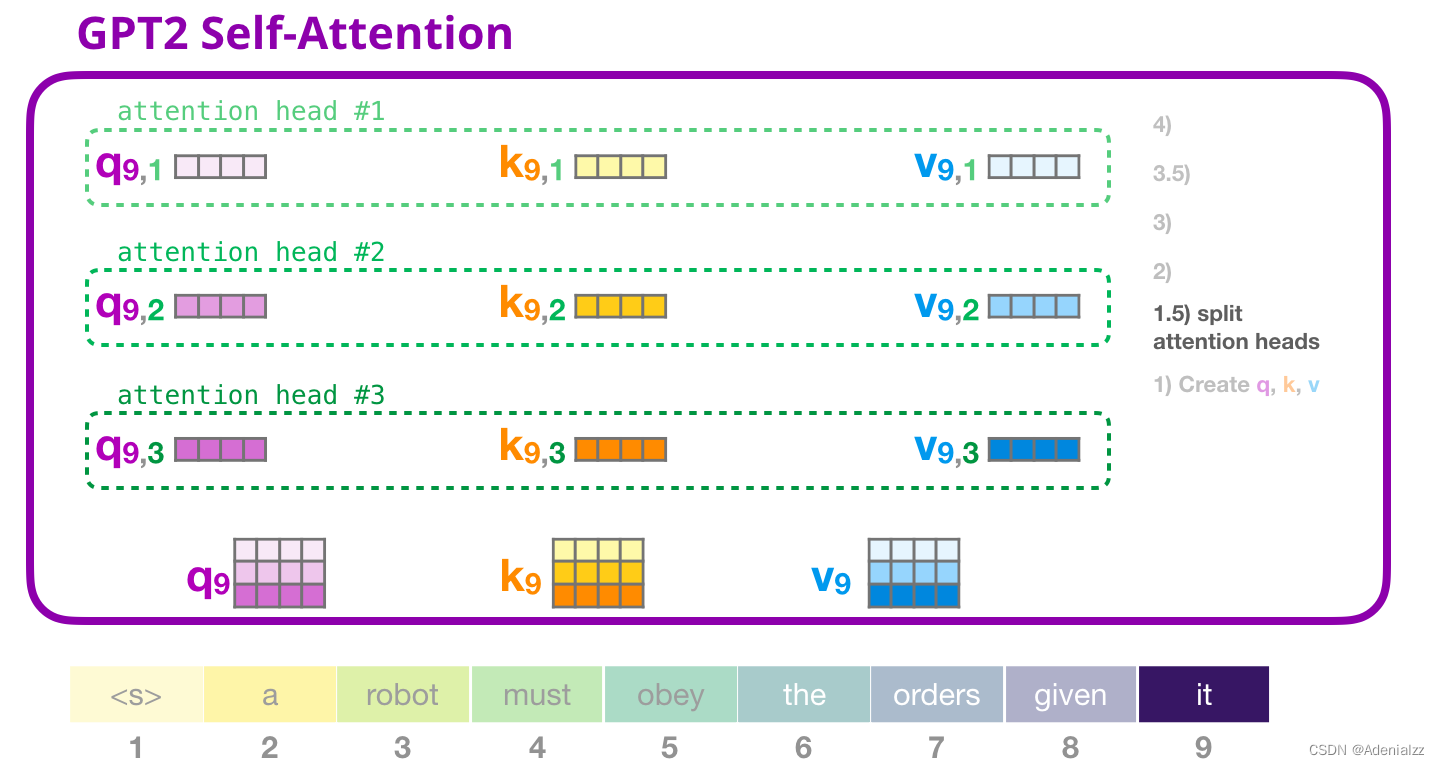
在前面的示例中�,我們介紹了一個(gè)注意力頭的情況�����。多個(gè)注意力頭可以想象成這樣(下圖為 12 個(gè)注意力頭中的 3 個(gè)的可視化結(jié)果):
GPT-2 自注意力機(jī)制:2-計(jì)算注意力得分
我們接下來介紹計(jì)算注意力得分的過程——此時(shí)我們只關(guān)注一個(gè)注意力頭(其它注意力頭都進(jìn)行類似的操作)���。
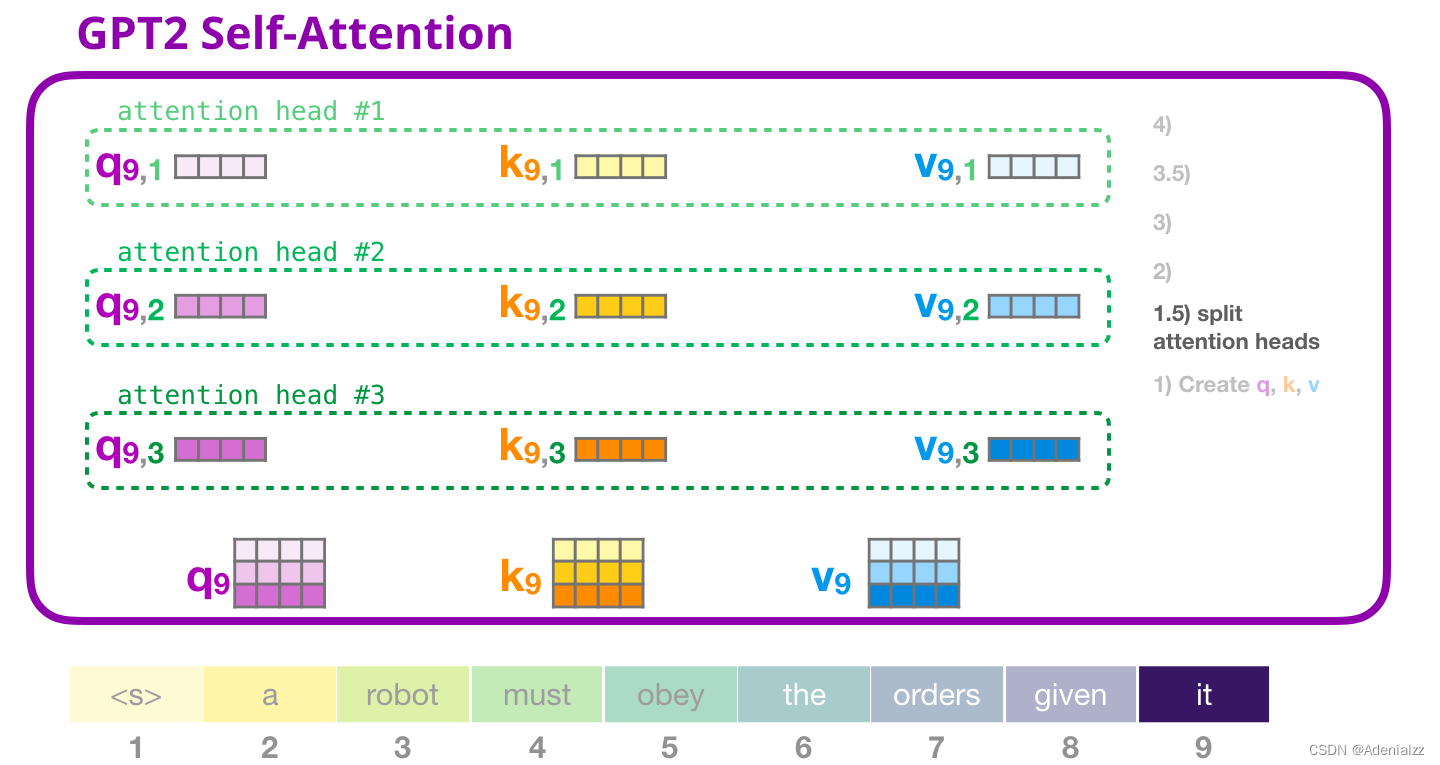
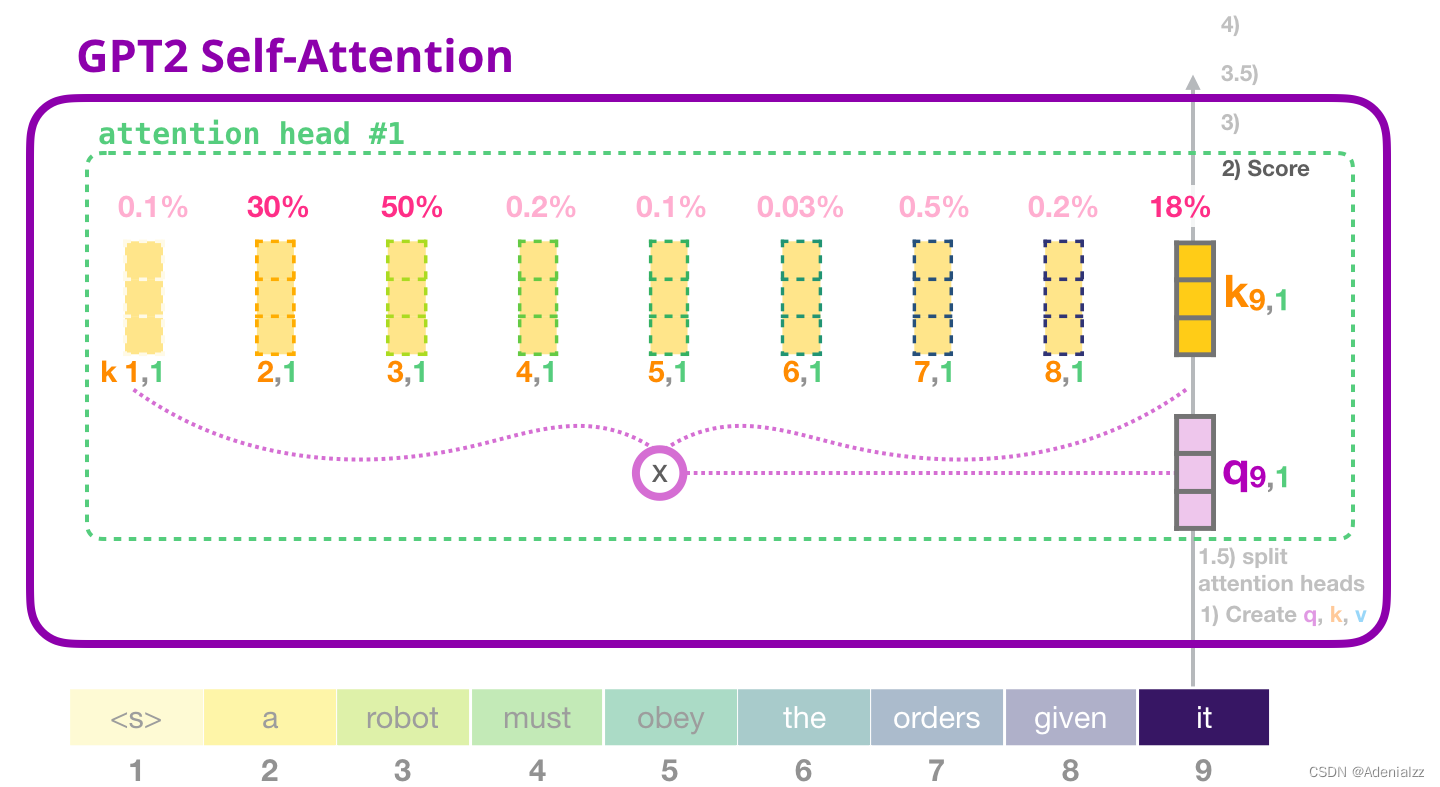
當(dāng)前關(guān)注的詞(token)可以對(duì)與其它鍵詞的鍵向量相乘得到注意力得分(在先前迭代中的第一個(gè)注意力頭中計(jì)算得到):
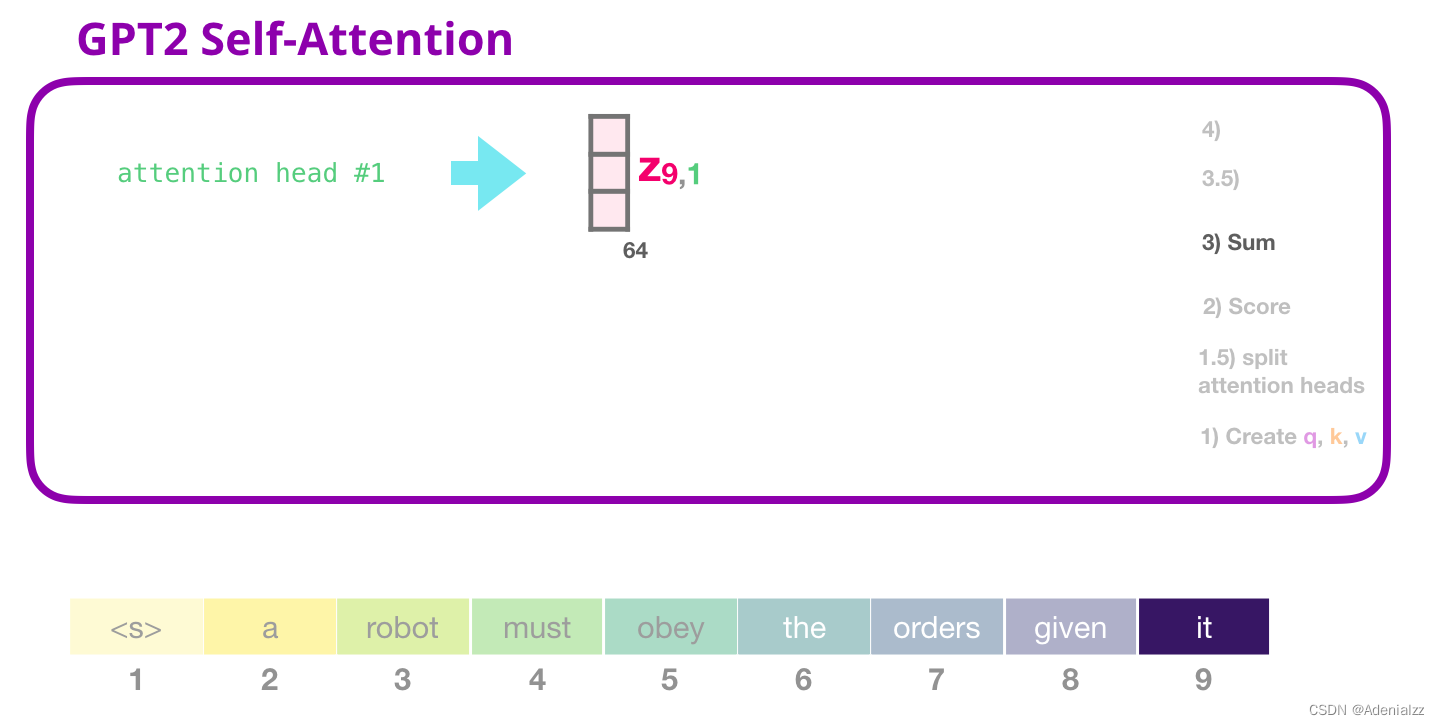
GPT-2 自注意力機(jī)制:3-求和
正如前文所述,我們現(xiàn)在可以將每個(gè)值向量乘上它的注意力得分���,然后求和,得到的是第一個(gè)注意力頭的自注意力結(jié)果:
GPT-2 自注意力機(jī)制:3.5-合并多個(gè)注意力頭
我們處理多個(gè)注意力頭的方式是先將它們連接成一個(gè)向量:
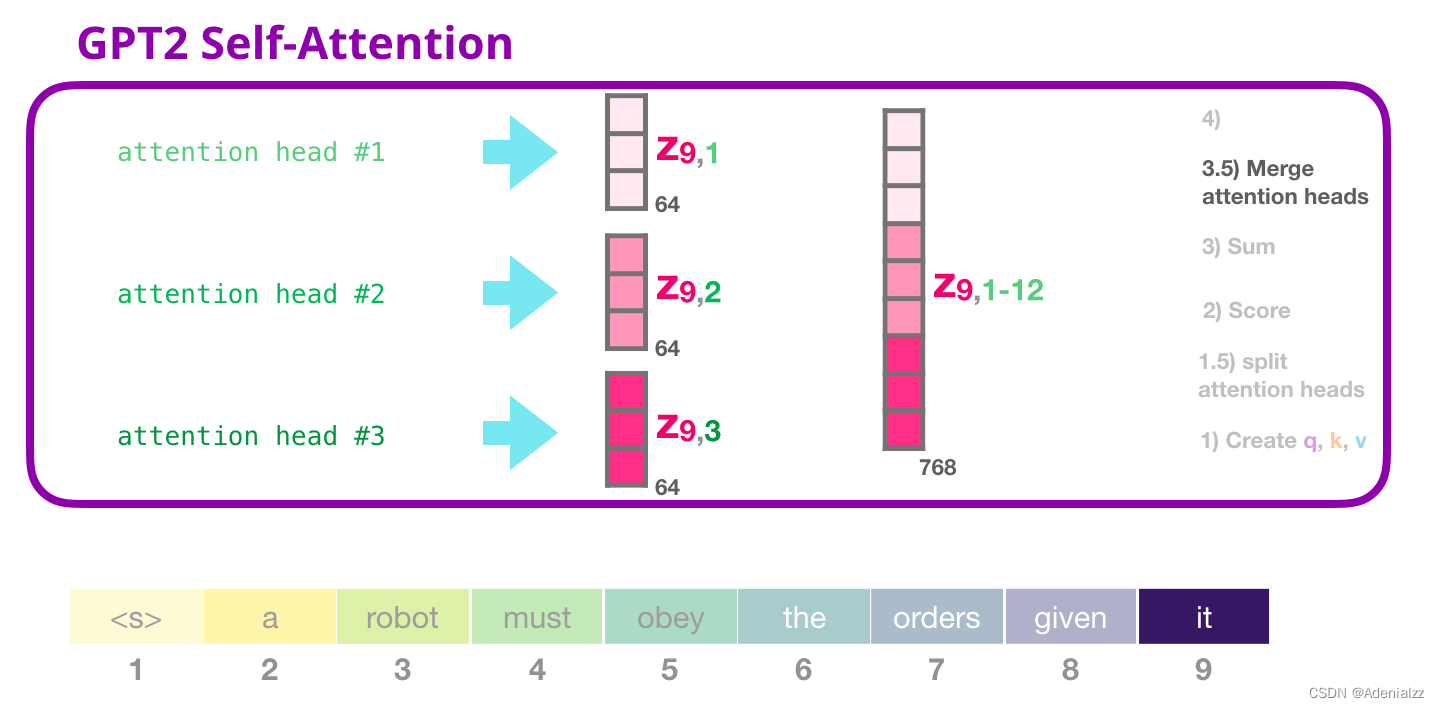
但是這個(gè)向量還不能被傳遞到下一個(gè)子層���。我們首先需要將這個(gè)隱含狀態(tài)的混合向量轉(zhuǎn)變成同質(zhì)的表示形式���。
GPT-2 自注意力機(jī)制:4-投影
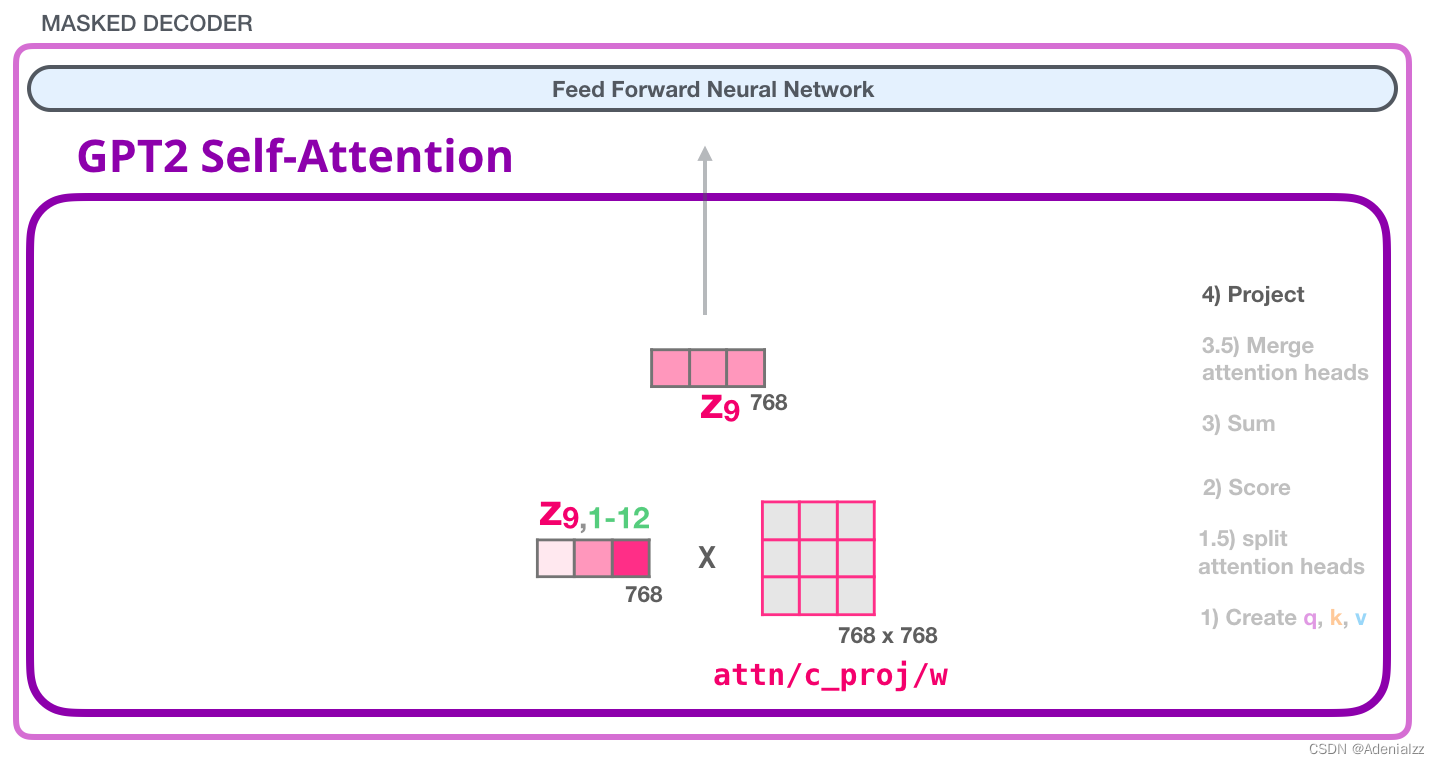
我們將讓模型學(xué)習(xí)如何最好地將連接好的自注意力結(jié)果映射到一個(gè)前饋神經(jīng)網(wǎng)絡(luò)可以處理的向量���。下面是我們的第二個(gè)大型權(quán)重矩陣,它將注意力頭的結(jié)果投影到自注意力子層的輸出向量中:
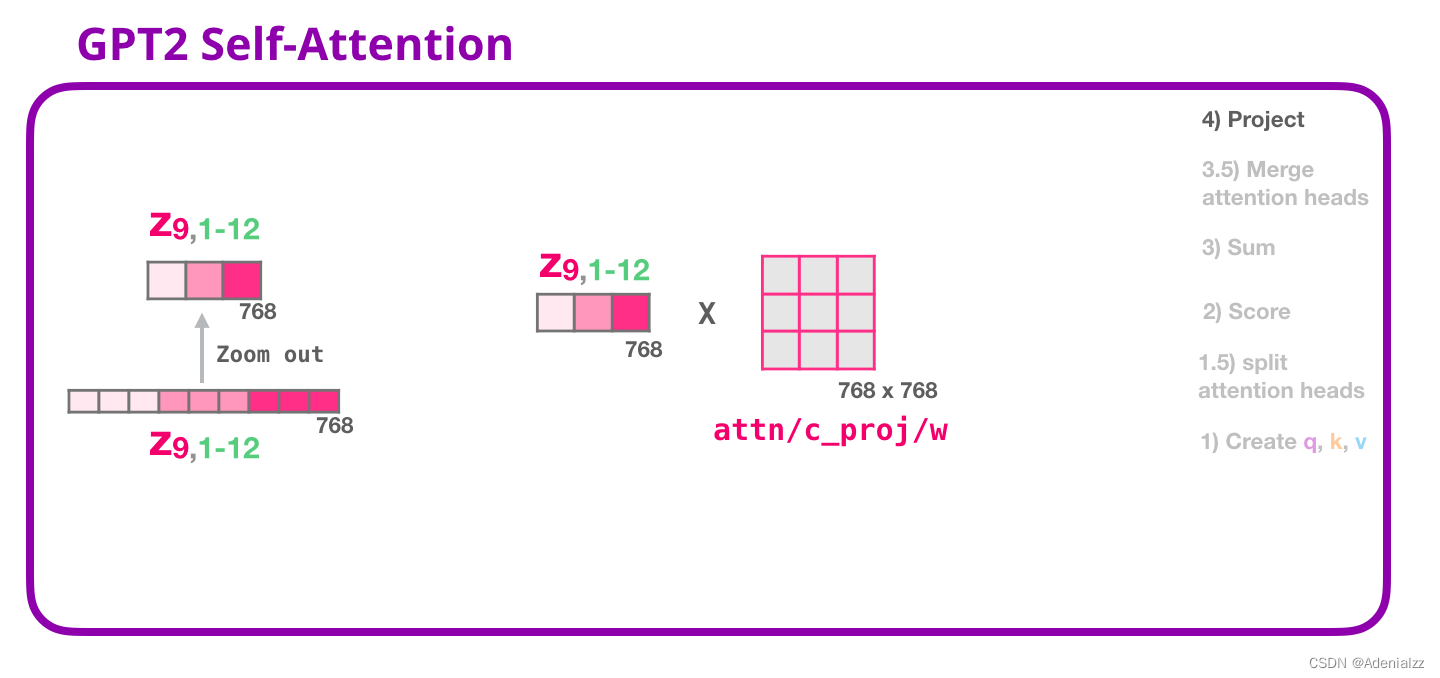
通過這個(gè)操作����,我們可以生成能夠傳遞給下一層的向量:
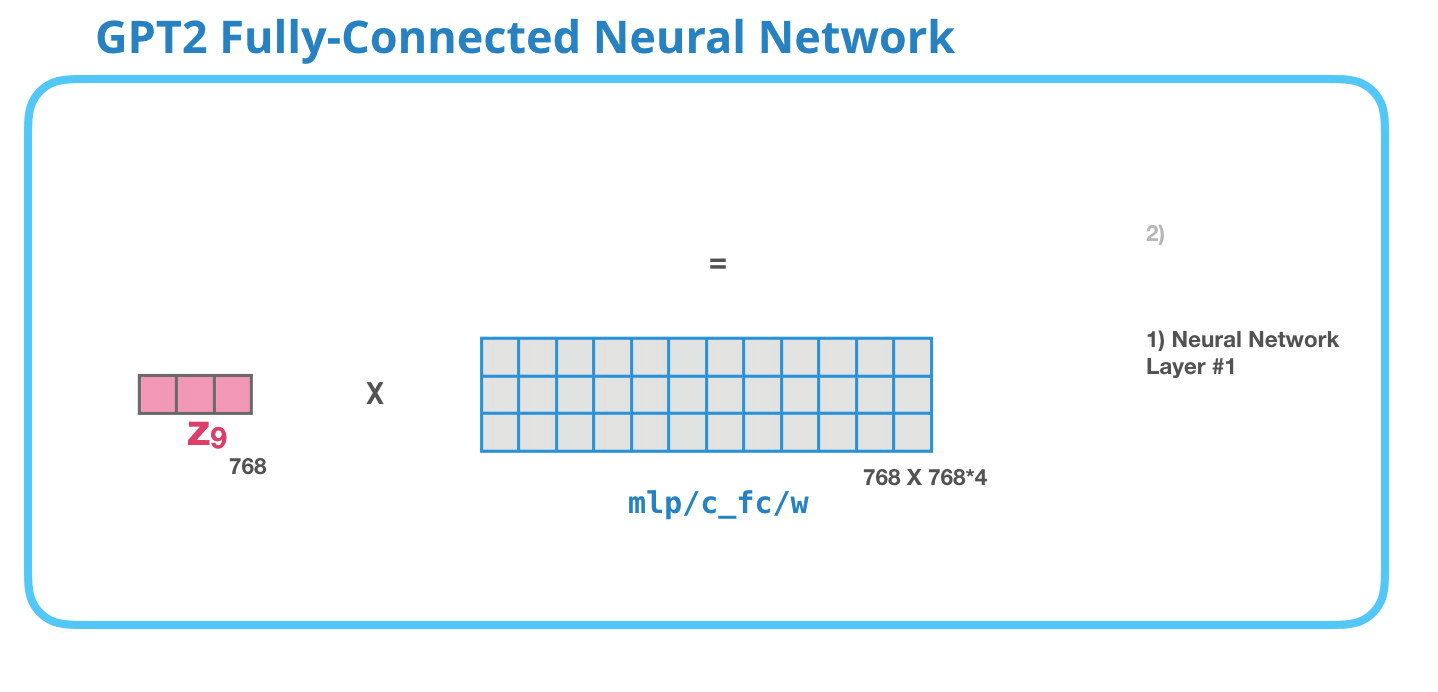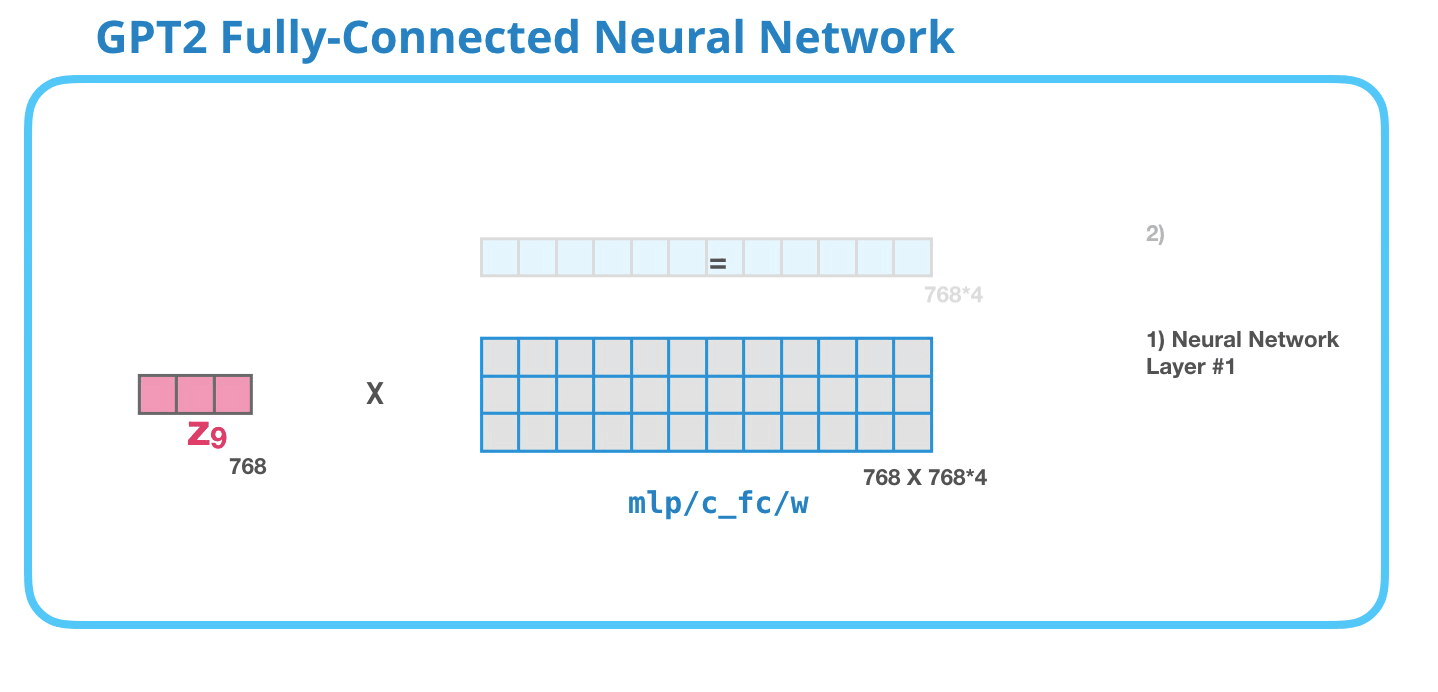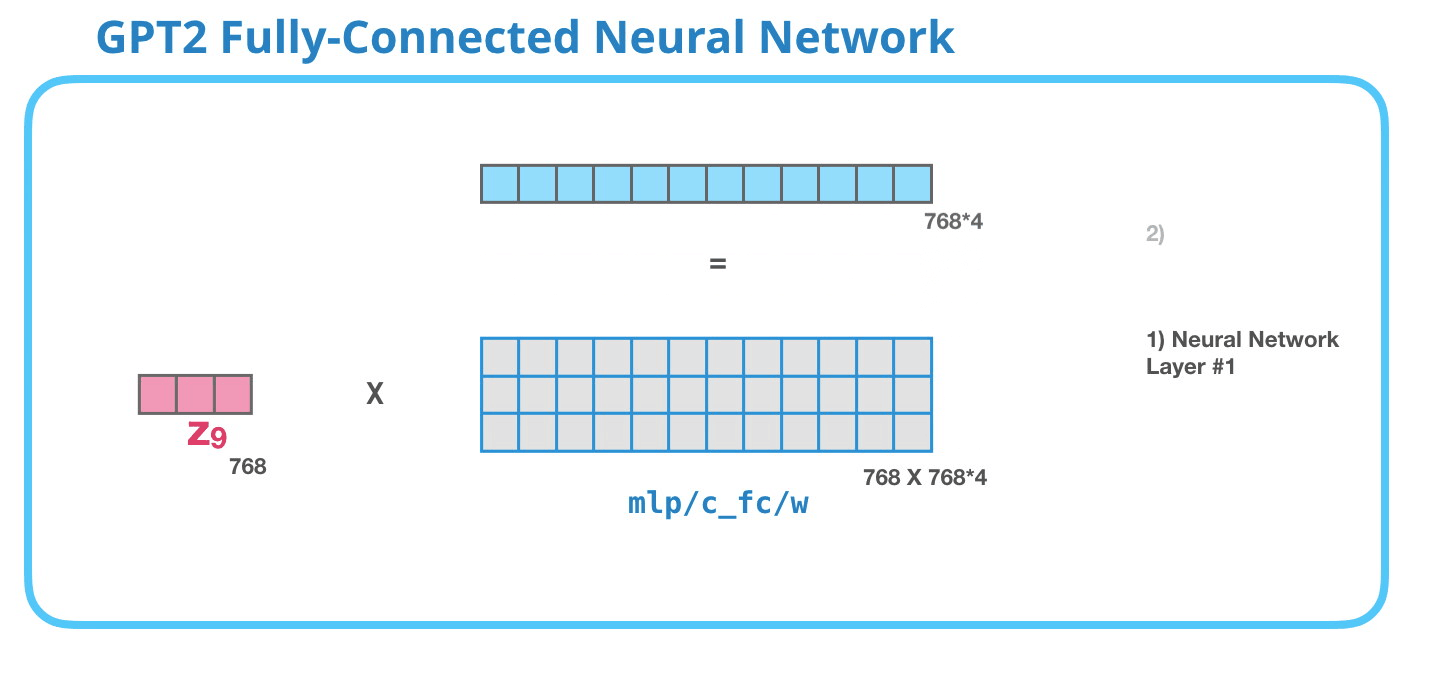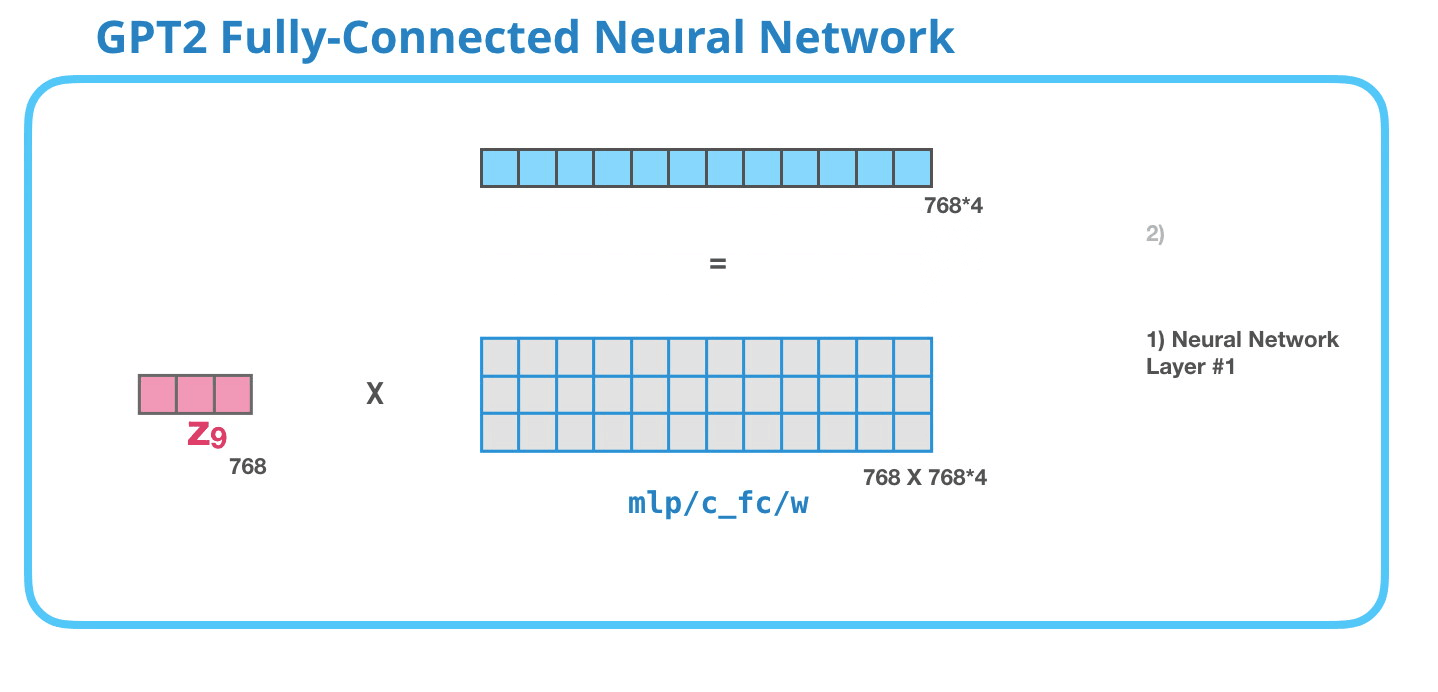
GPT-2 全連神經(jīng)網(wǎng)絡(luò):第一層
在全連接神經(jīng)網(wǎng)絡(luò)中����,當(dāng)自注意力機(jī)制已經(jīng)將合適的上下文包含在其表征中之后�����,模塊會(huì)處理它的輸入詞�。它由兩層組成:第一層的大小是模型的 4 倍(因?yàn)樾⌒?GPT-2 的大小為 768 個(gè)單元��,而這個(gè)網(wǎng)絡(luò)將有 768*4=3072 個(gè)單元)�。為什么是 4 倍呢�?這只是原始 transformer 的運(yùn)行大小(模型維度為 512 而模型的第一層為 2048)����。這似乎給 transformer 模型足夠的表征容量來處理目前面對(duì)的任務(wù)����。
GPT-2 全連神經(jīng)網(wǎng)絡(luò):第二層-投影到模型的維度
第二層將第一層的結(jié)果投影回模型的維度大?����。ㄐ⌒?GPT-2 的大小為 768)��。這個(gè)乘法結(jié)果是該詞經(jīng)過 transformer 模塊處理的結(jié)果。
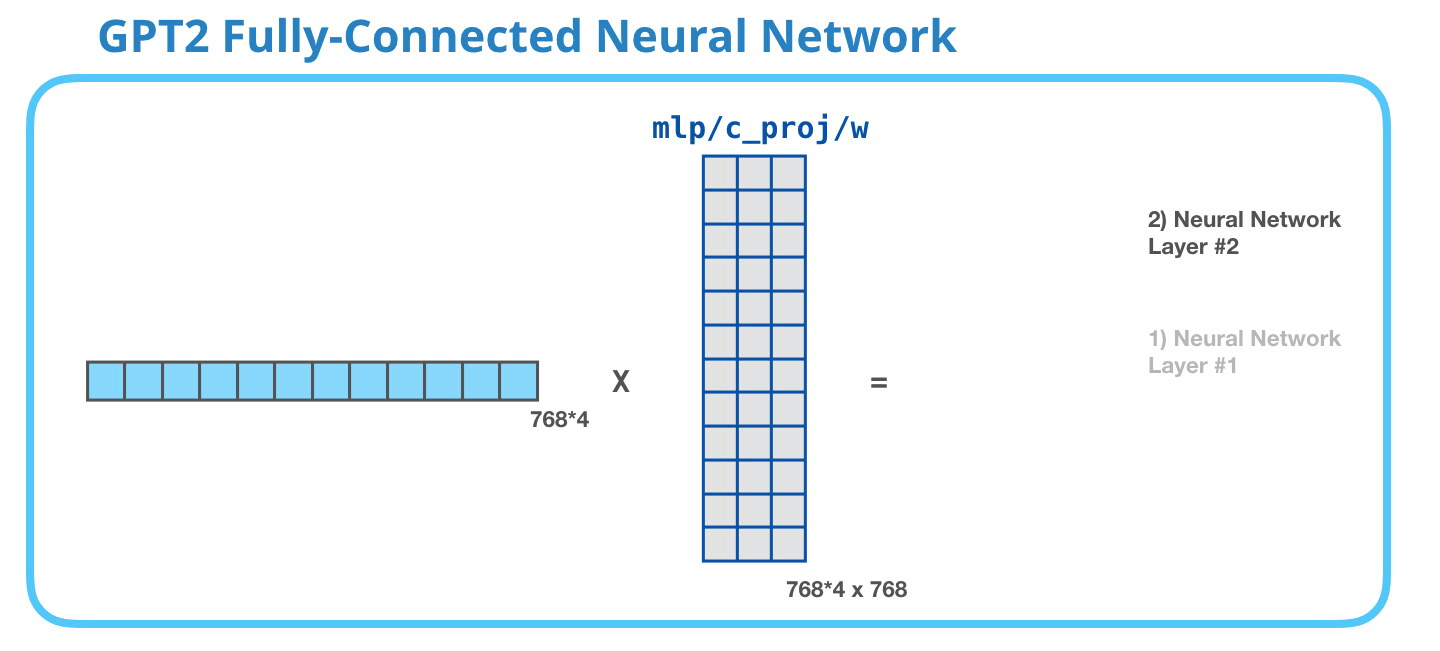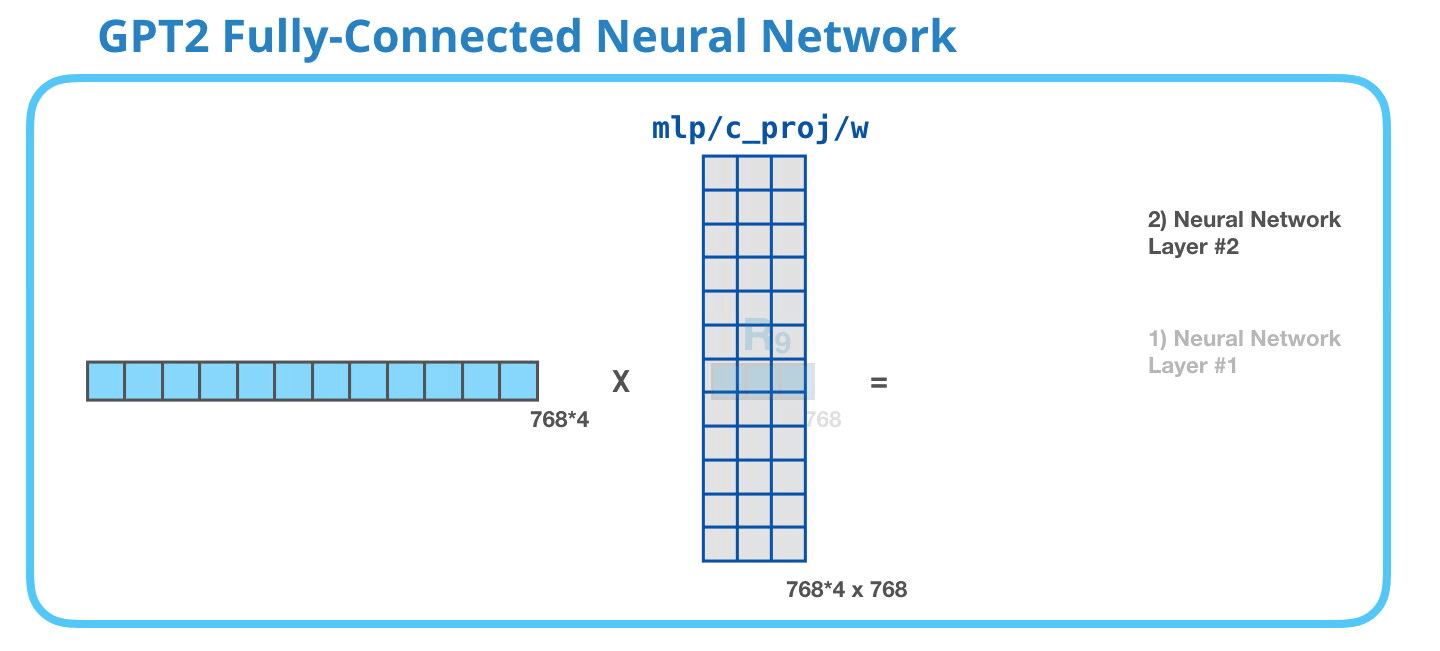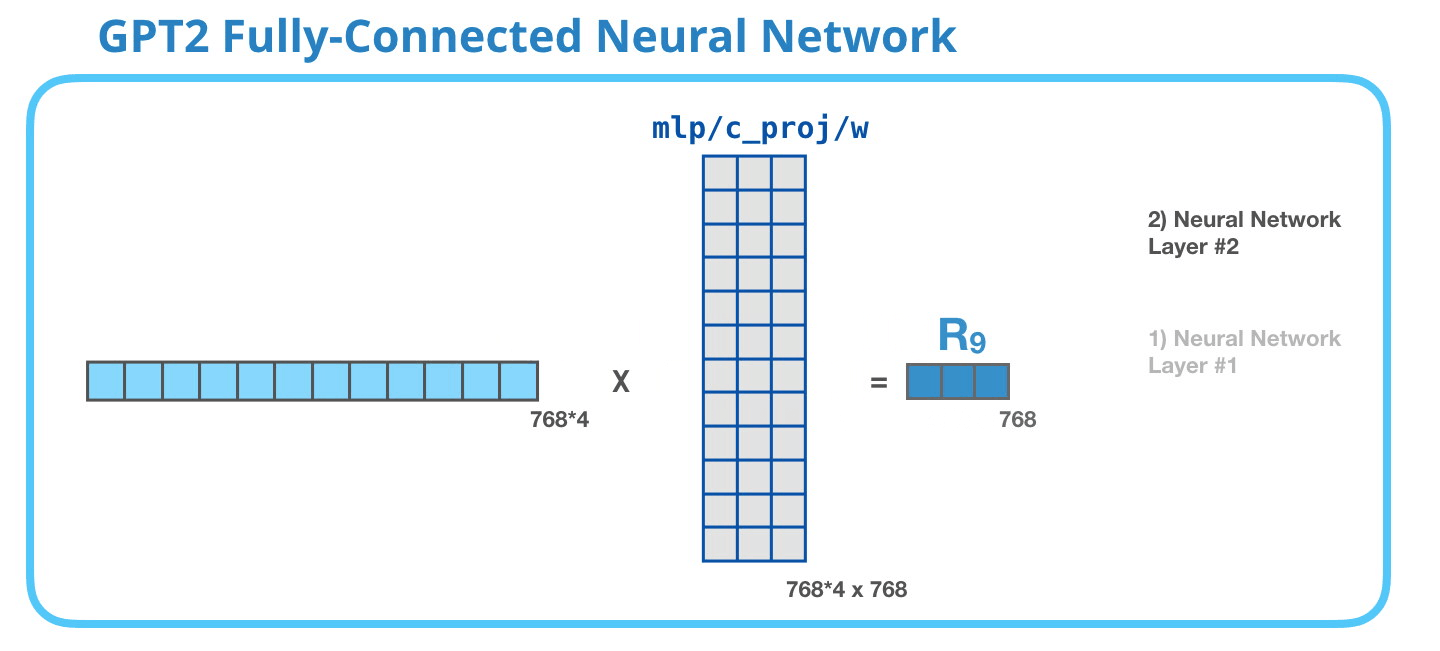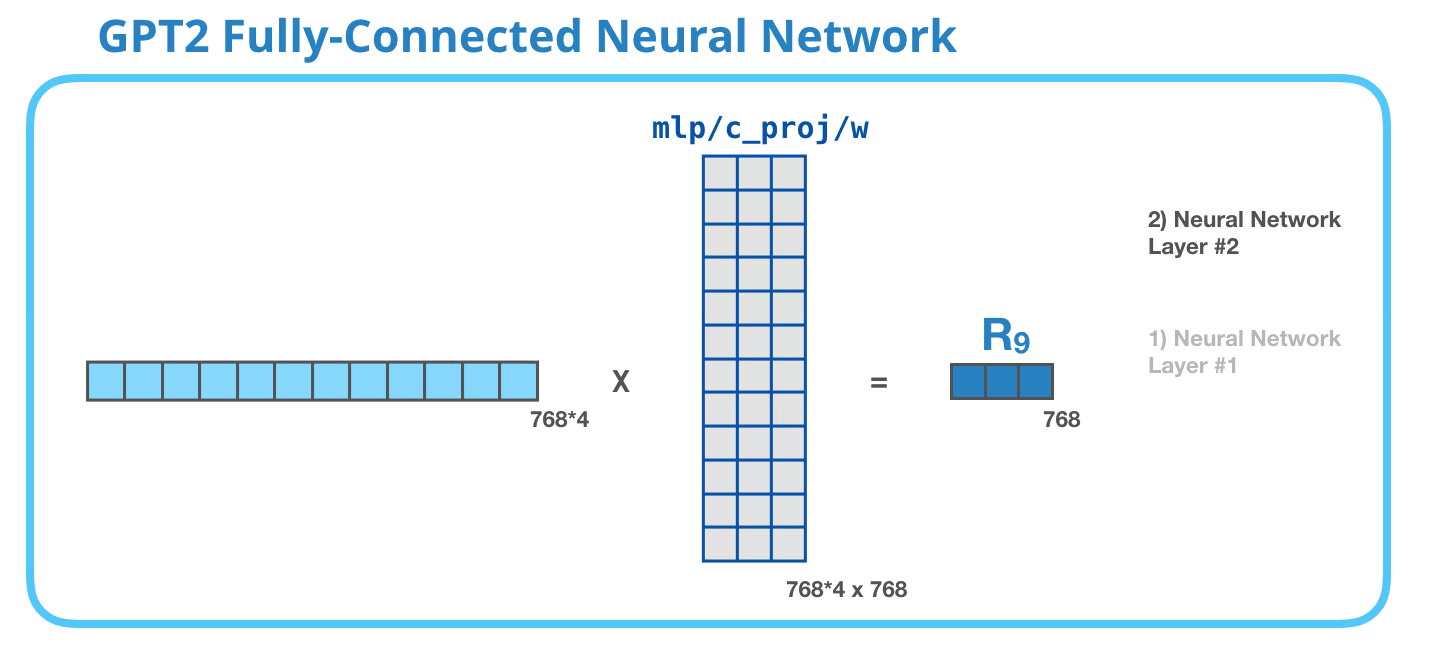
你成功處理完單詞「it」了���!
我們盡可能詳細(xì)地介紹了 transformer 模塊。現(xiàn)在�,你已經(jīng)基本掌握了 transformer 語言模型內(nèi)部發(fā)生的絕大部分情況了��?����;仡櫼幌?�,一個(gè)新的輸入向量會(huì)遇到如下所示的權(quán)重矩陣:
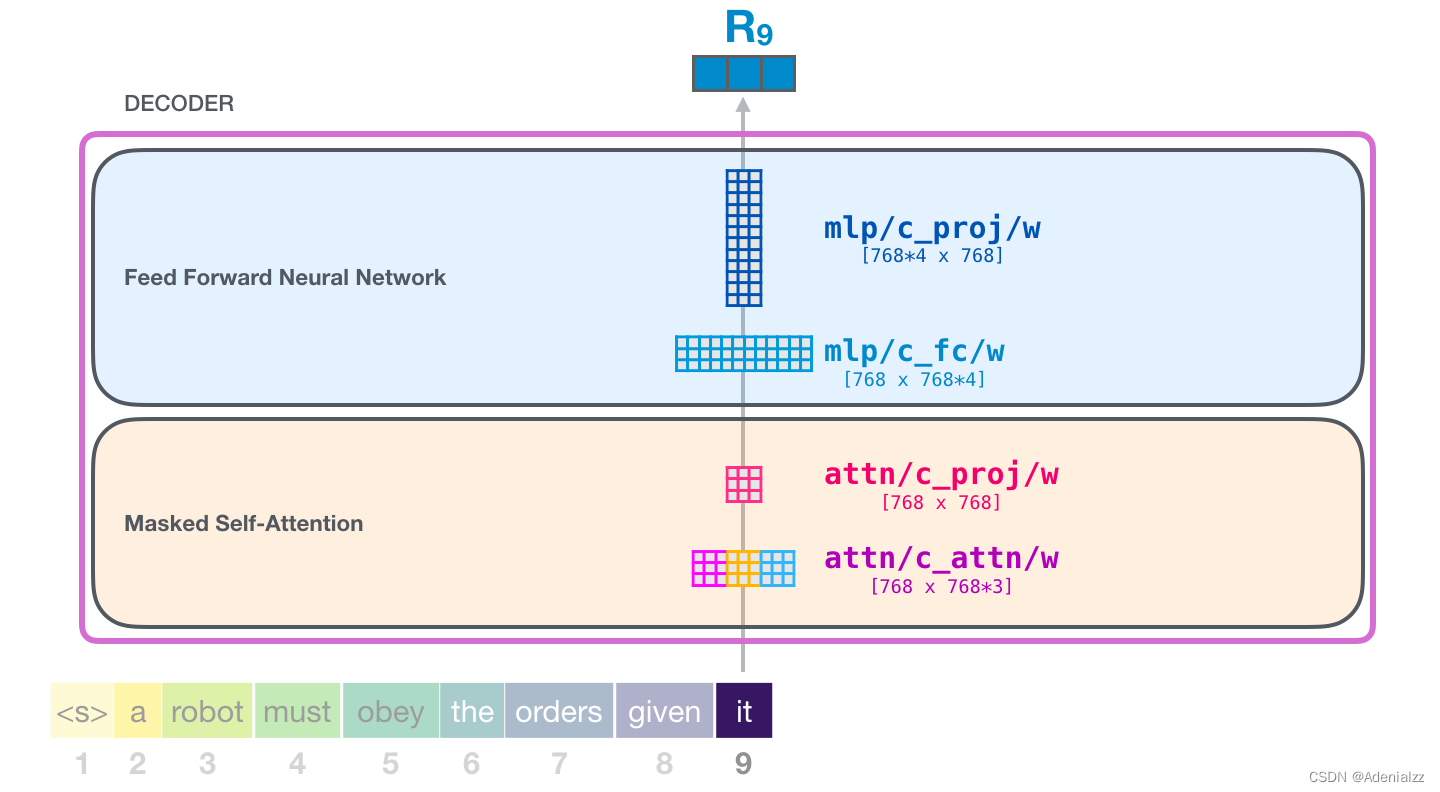
而且每個(gè)模塊都有自己的一組權(quán)重。另一方面�����,這個(gè)模型只有一個(gè)詞嵌入矩陣和一個(gè)位置編碼矩陣:
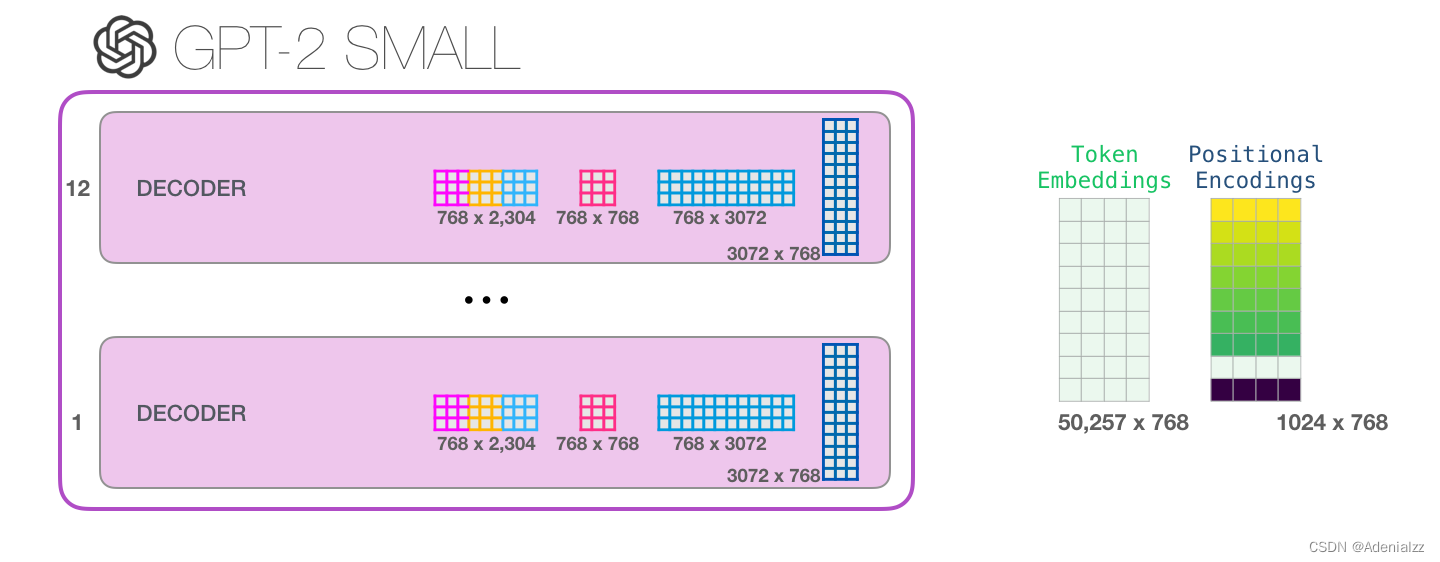
如果你想了解模型中的所有參數(shù)�,下面是對(duì)它們的詳細(xì)統(tǒng)計(jì)結(jié)果:
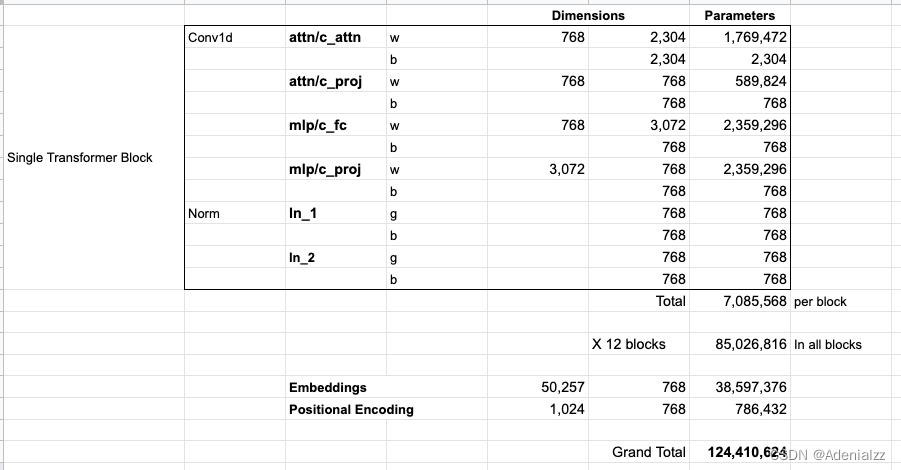
出于某些原因�����,該模型共計(jì)有 1 億 2,400 萬個(gè)參數(shù)而不是 1 億 1,700 萬個(gè)����。我不確定這是為什么����,但是這似乎就是發(fā)布的代碼中的數(shù)目(如果本文統(tǒng)計(jì)有誤���,請(qǐng)讀者指正)��。
第三部分:語言建模之外
只包含解碼器的 transformer 不斷地表現(xiàn)出在語言建模之外的應(yīng)用前景�。在許多應(yīng)用程序中��,這類模型已經(jīng)取得了成功�,它可以用與上面類似的可視化圖表來描述����。在文章的最后,讓我們一起來回顧一下其中的一些應(yīng)用�。
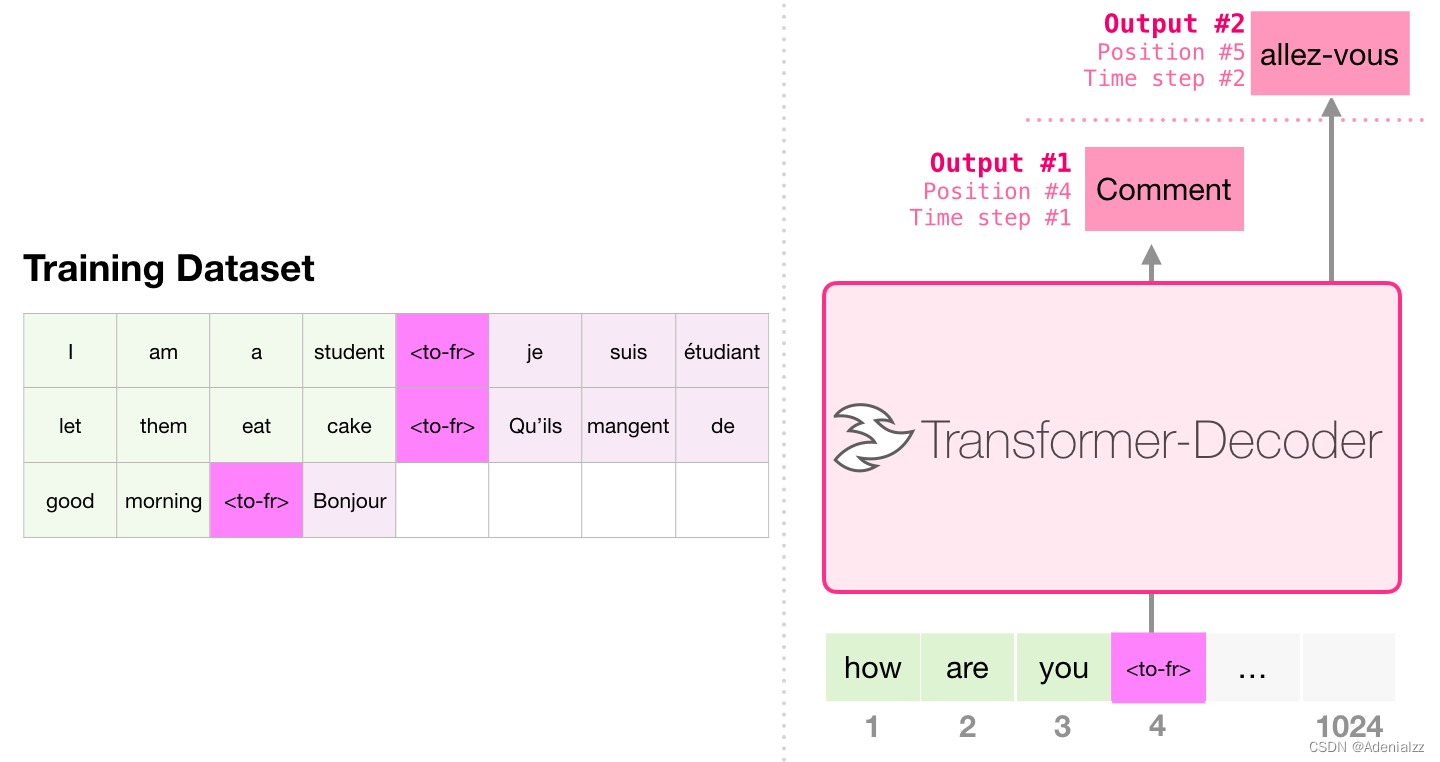
機(jī)器翻譯
進(jìn)行翻譯時(shí)���,模型不需要編碼器。同樣的任務(wù)可以通過一個(gè)只有解碼器的 transformer 來解決:
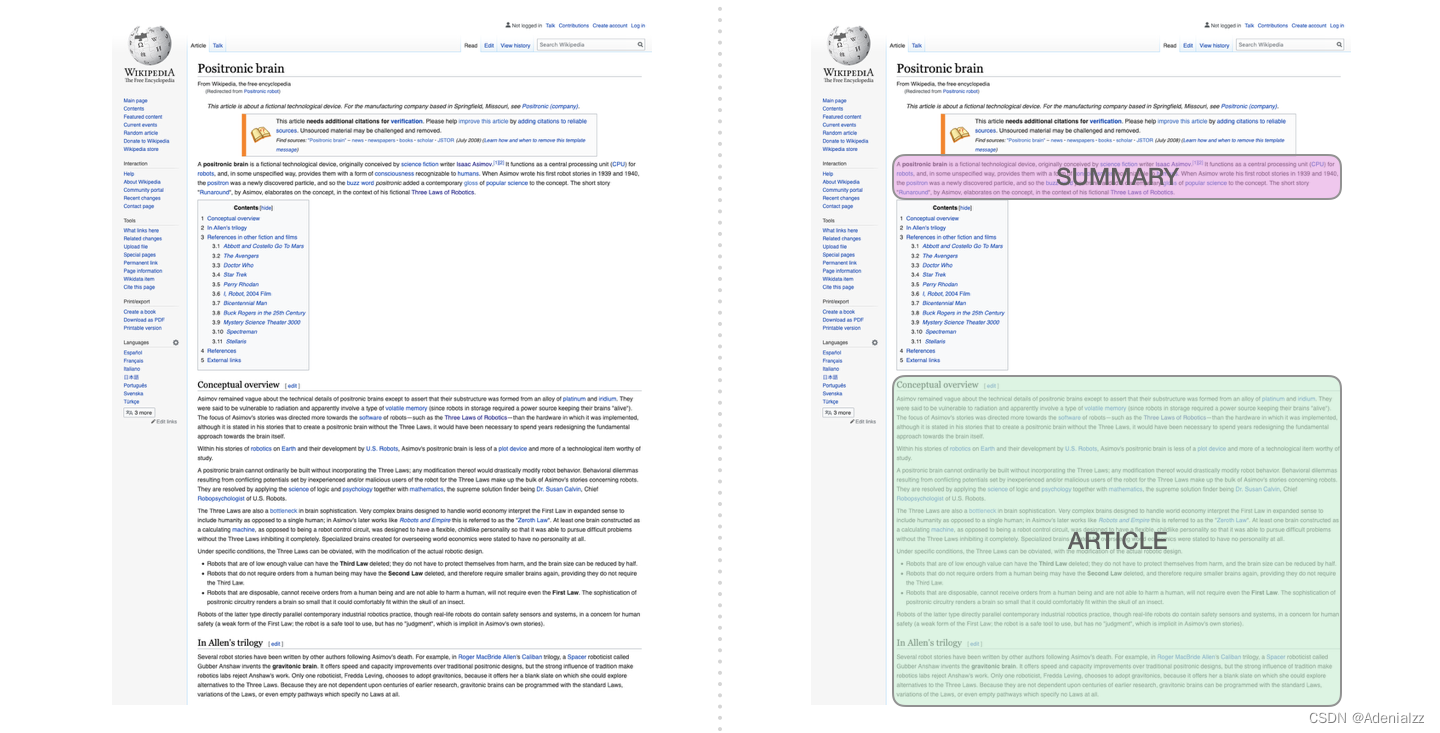
自動(dòng)摘要生成
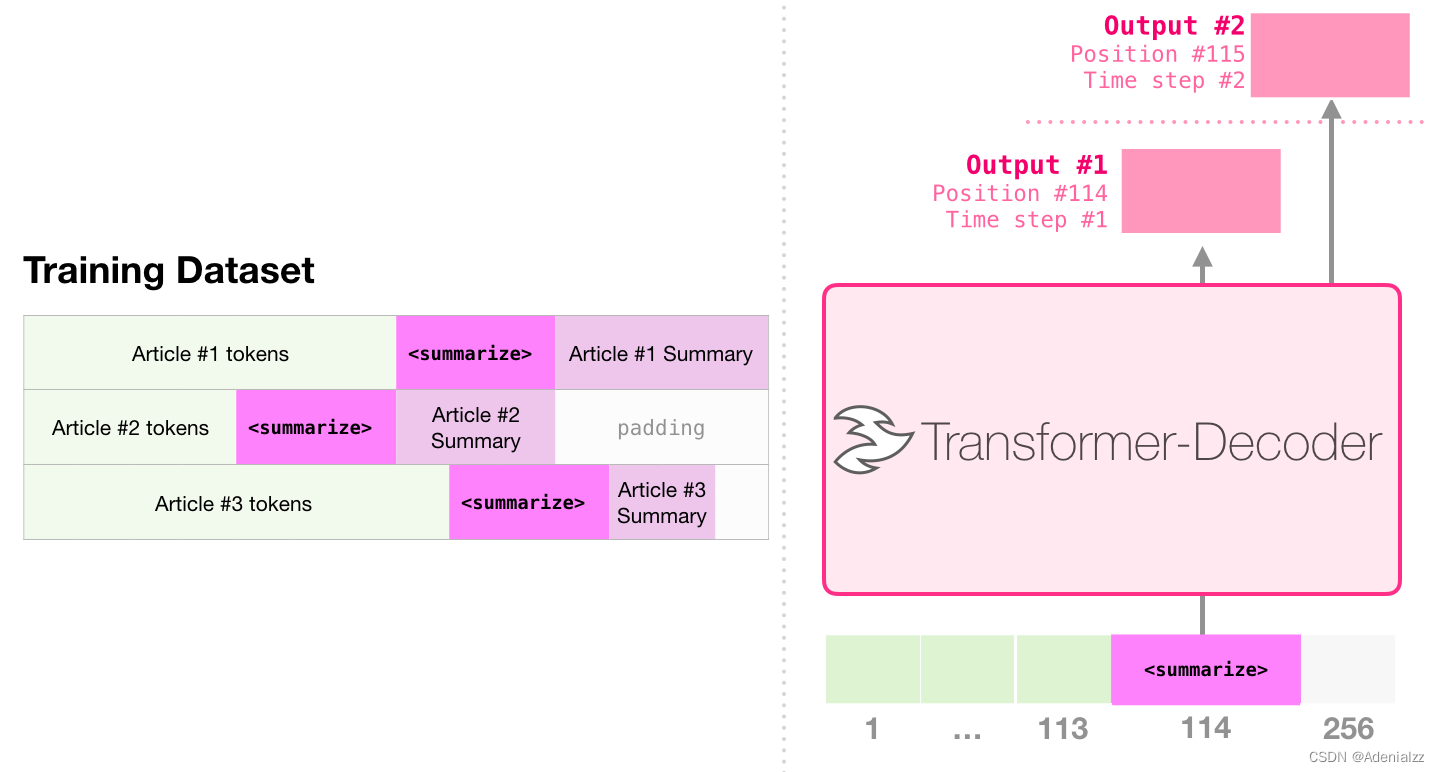
這是第一個(gè)訓(xùn)練只包含解碼器的 transformer 的任務(wù)�����。也就是說,該模型被訓(xùn)練來閱讀維基百科的文章(沒有目錄前的開頭部分)��,然后生成摘要�����。文章實(shí)際的開頭部分被用作訓(xùn)練數(shù)據(jù)集的標(biāo)簽:
論文使用維基百科的文章對(duì)模型進(jìn)行了訓(xùn)練��,訓(xùn)練好的模型能夠生成文章的摘要:
遷移學(xué)習(xí)
在論文 Sample Efficient Text Summarization Using a Single Pre-Trained Transformer 中,首先使用只包含解碼器的 transformer 在語言建模任務(wù)中進(jìn)行預(yù)訓(xùn)練���,然后通過調(diào)優(yōu)來完成摘要生成任務(wù)。結(jié)果表明��,在數(shù)據(jù)有限的情況下��,該方案比預(yù)訓(xùn)練好的編碼器-解碼器 transformer 得到了更好的效果���。
GPT2 的論文也展示了對(duì)語言建模模型進(jìn)行預(yù)訓(xùn)練后取得的摘要生成效果����。
音樂生成
音樂 transformer 采用了只包含解碼器的 transformer 來生成具有豐富節(jié)奏和動(dòng)感的音樂。和語言建模相似�����,「音樂建?��!咕褪亲屇P鸵砸环N無監(jiān)督的方式學(xué)習(xí)音樂����,然后讓它輸出樣本(我們此前稱之為「隨機(jī)工作」)�。
你可能會(huì)好奇,在這種情境下是如何表征音樂的�����?請(qǐng)記住,語言建??梢酝ㄟ^對(duì)字符���、單詞(word)、或單詞(word)某個(gè)部分的詞(token)的向量表征來實(shí)現(xiàn)��。面對(duì)一段音樂演奏(暫時(shí)以鋼琴為例)���,我們不僅要表征這些音符,還要表征速度——衡量鋼琴按鍵力度的指標(biāo)����。
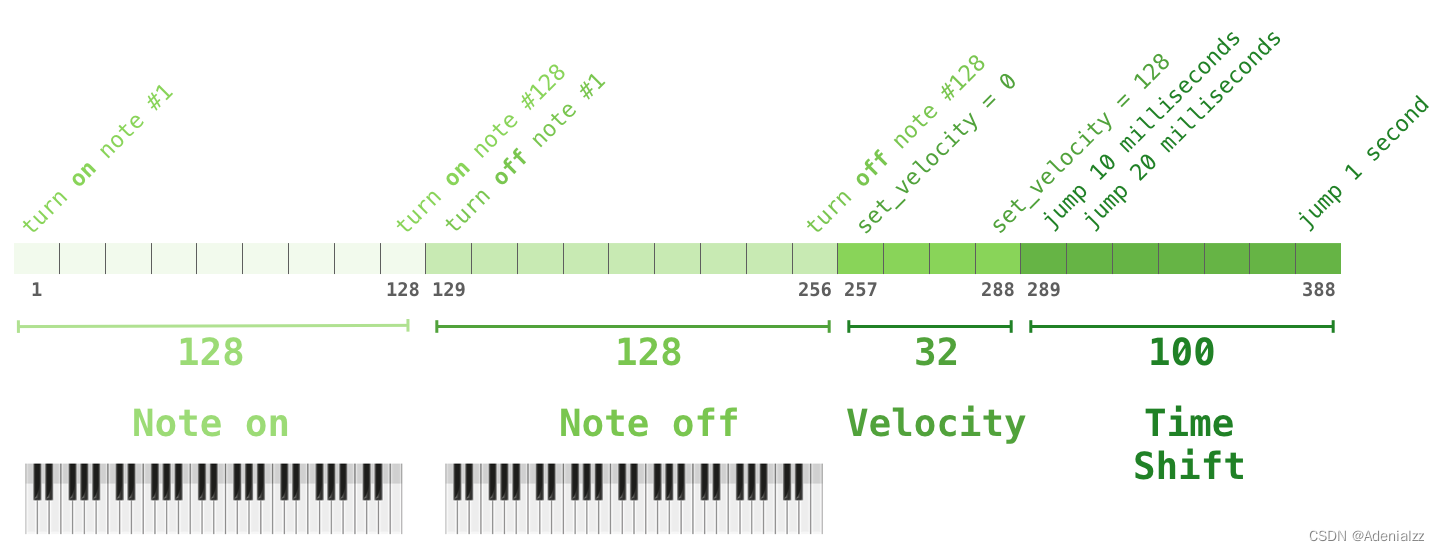
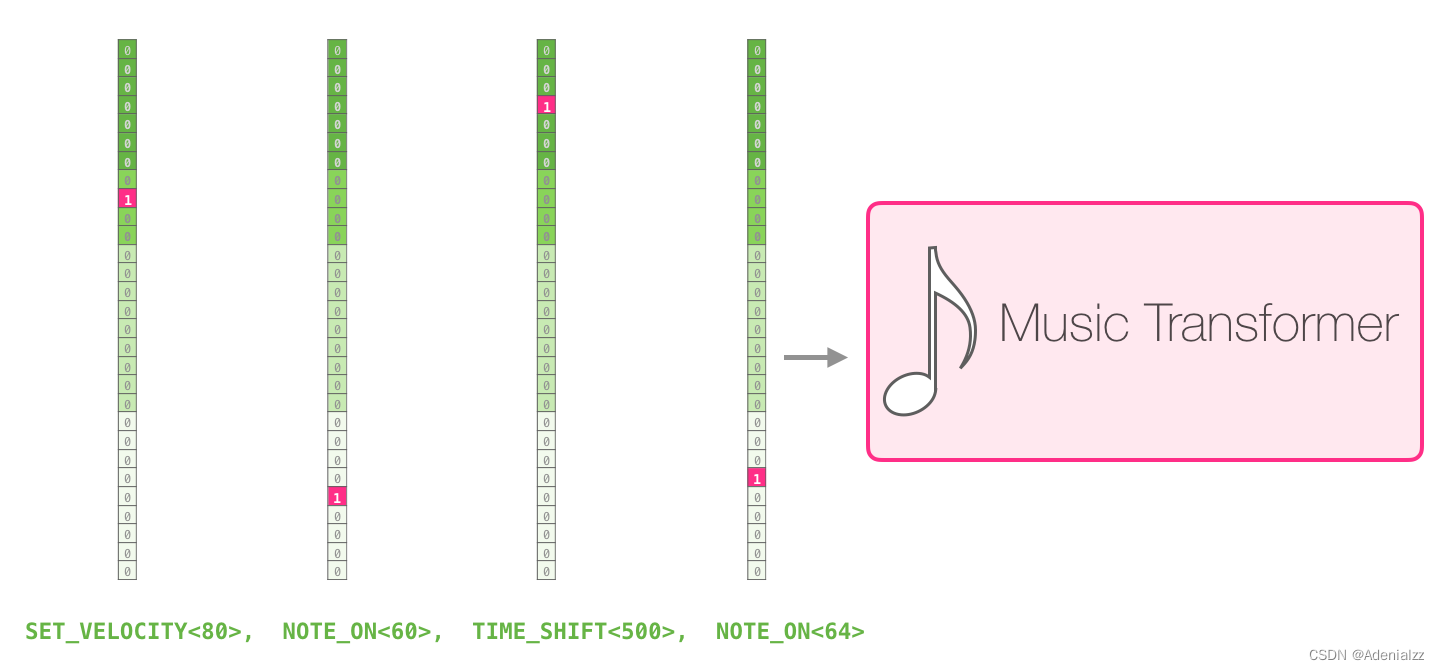
一段演奏可以被表征為一系列的 one-hot 向量�。一個(gè) MIDI 文件可以被轉(zhuǎn)換成這樣的格式。論文中展示了如下所示的輸入序列的示例����。

這個(gè)輸入序列的 one-hot 向量表征如下:
我喜歡論文中用來展示音樂 transformer 中自注意力機(jī)制的可視化圖表�。我在這里加了一些注釋:
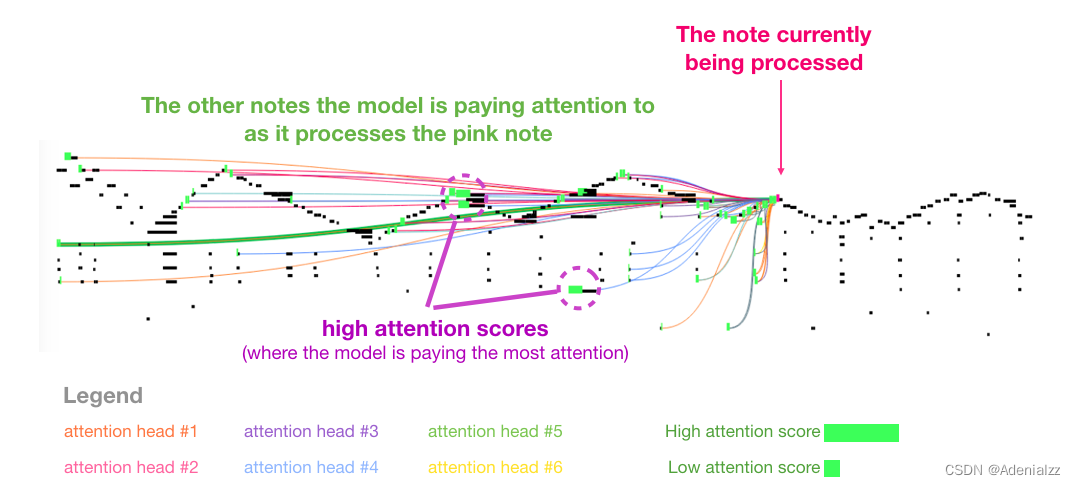
這段作品中出現(xiàn)了反復(fù)出現(xiàn)的三角輪廓����。當(dāng)前的查詢向量位于后面一個(gè)「高峰」,它關(guān)注前面所有高峰上的高音�����,一直到樂曲的開頭�。圖中顯示了一個(gè)查詢向量(所有的注意力線來源)和正要處理的以前的記憶(突出了有更高 softmax 概率的音符)����。注意力線的顏色對(duì)應(yīng)于不同的注意力頭,而寬度對(duì)應(yīng)于 softmax 概率的權(quán)重�。
如果你想進(jìn)一步了解這種音符的表征,請(qǐng)觀看視頻�。
結(jié)語
至此�����,我們的 GPT-2 的完全解讀����,以及對(duì)父類模型(只包含解碼器的 transformer)的分析就到此結(jié)束了。希望讀者能通過這篇文章對(duì)自注意力機(jī)制有更好的理解�����。在了解了 transformer 內(nèi)部的工作原理之后�����,下次再遇到它�,你將更加得心應(yīng)手。
該文章在 2024/1/16 8:48:34 編輯過


 400 186 1886
400 186 1886
晴公司官網(wǎng)")


晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")


