這些文件在硬盤看來���,就是一堆二進(jìn)制數(shù)據(jù)而已你準(zhǔn)備把這些文件存儲在硬盤上�,并在需要的時(shí)候讀取出來。要設(shè)計(jì)怎樣的軟件�,才能更方便地在硬盤中讀寫這些文件呢�?
1
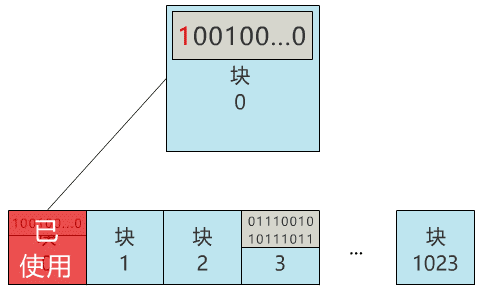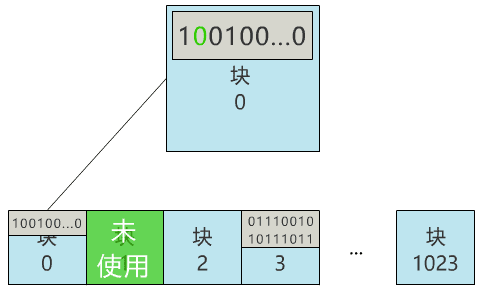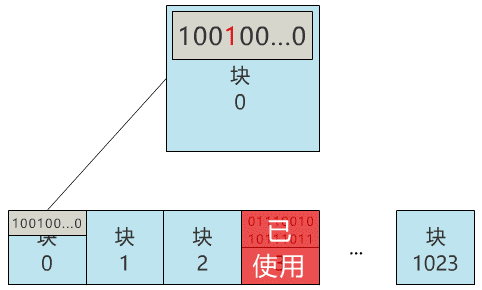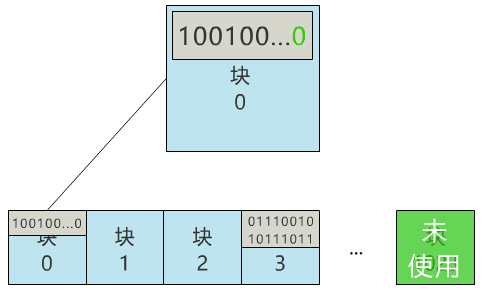
首先我不想和復(fù)雜的扇區(qū)���,設(shè)備驅(qū)動(dòng)等細(xì)節(jié)打交道���,因此我先實(shí)現(xiàn)了一個(gè)簡單的功能,將硬盤按邏輯分成一個(gè)個(gè)的塊�,并可以以塊為單位進(jìn)行讀寫。每個(gè)塊就定義為兩個(gè)物理扇區(qū)的大小�,即 1024 字節(jié),就是 1KB 啦����。硬盤太大不好分析,我們就假設(shè)你的硬盤只有 1MB����,那么這塊硬盤則有 1024 個(gè)塊。隨便選個(gè)塊放進(jìn)去��,3 號塊吧�����!
誒�����?發(fā)現(xiàn)問題了���,萬一這個(gè)文件也存到了 3 號塊,不是把原來的文件覆蓋了么���?不行��,得有一個(gè)地方記錄���,現(xiàn)在可使用的塊有哪些,像這樣���。
塊 0:未使用
塊 1:未使用
塊 2:未使用
塊 3:已使用
塊 4:未使用
...
塊 1023:未使用
那我們就用 0 號塊���,來記錄所有塊的使用情況吧�!怎么記錄呢���?那我們給塊 0 起個(gè)名字��,叫塊位圖���,之后這個(gè)塊 0 就專門用來記錄所有塊的使用情況,不再用來存具體文件了�。當(dāng)我們再存入一個(gè)新文件時(shí),只需要在塊位圖中找到第一個(gè)為 0 的位���,就可以找到第一個(gè)還未被使用的塊����,將文件存入����。同時(shí),別忘了把塊位圖中的相應(yīng)位置 1。
咦?又遇到問題了�����,我怎么找到剛剛的文件呢�?根據(jù)塊號么�?這也太蠢了,就像你去書店找書�����,店員讓你提供書的編號�,而不是書名,顯然不合理����。因此我們給每個(gè)文件起一個(gè)名字,叫文件名,通過它來尋找這個(gè)文件��。那必然就要有一個(gè)地方�����,記錄文件名與塊號的對應(yīng)關(guān)系�,像這樣。
葵花寶典.txt:3 號塊
數(shù)學(xué)期末復(fù)習(xí)資料.mp4:5 號塊
無聊的閃客.pdf:10 號塊
...
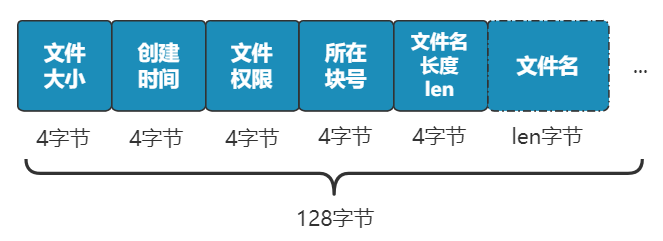
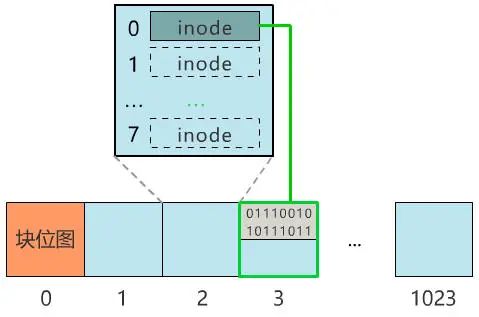
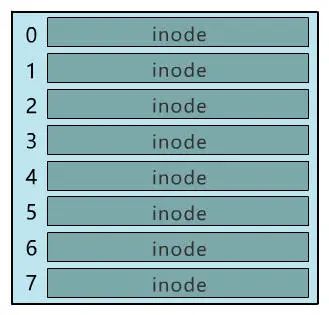
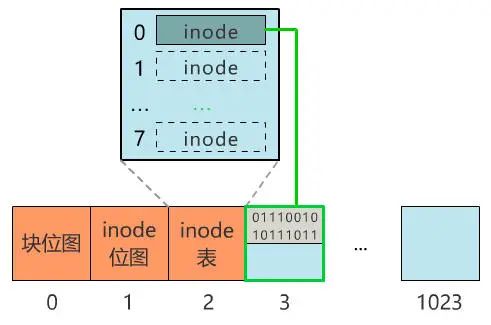
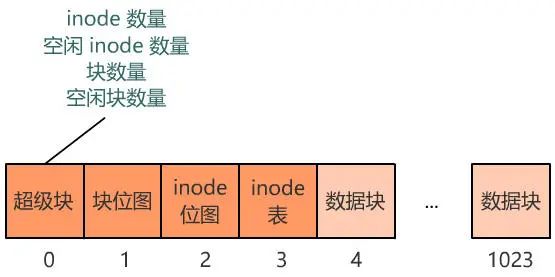
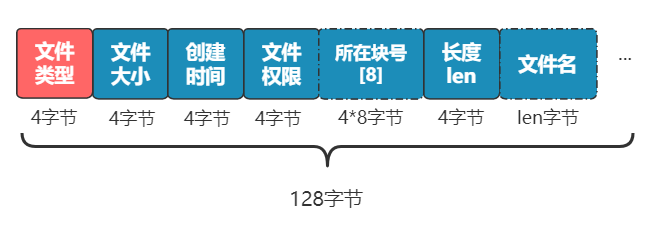
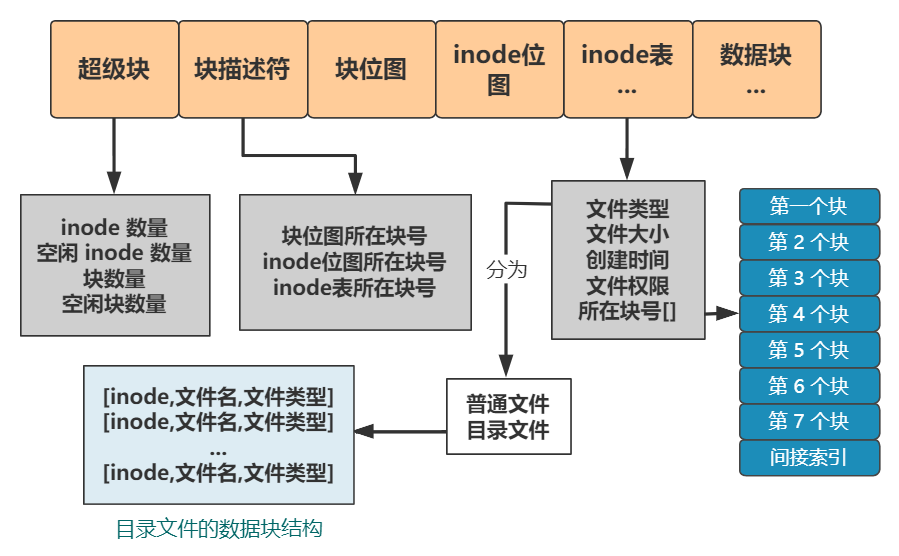
別急���,既然都要選一個(gè)地方記錄文件名稱了��,不妨多記錄一點(diǎn)我們關(guān)心的信息吧�����,比如文件大小�、文件創(chuàng)建時(shí)間�����、文件權(quán)限等�����。這些東西自然也要保存在硬盤上,我們選擇用一個(gè)固定大小的空間���,來表示這些信息�����,多大空間呢���?128 字節(jié)吧。為啥是 128 字節(jié)呢���?我樂意��。我們將這 128 字節(jié)的結(jié)構(gòu)體��,叫做一個(gè) inode。之后���,我們每存入一個(gè)新的文件��,不但要占用一個(gè)塊來存放這個(gè)文件本身���,還要占用一個(gè) inode 來存放文件的這些元信息,并且這個(gè) inode 的所在塊號這個(gè)字段,就指向這個(gè)文件所在的塊號�。如果一個(gè) inode 為 128 字節(jié),那么一個(gè)塊就可以容納 8 個(gè) inode��,我們可以將這些 inode 編上號�。如果你覺得 inode 數(shù)不夠,也可以用兩個(gè)或者多個(gè)塊來存放 inode 信息�,但這樣用于存放數(shù)據(jù)的塊就少了,這就看你自己的平衡了�。同樣,和塊位圖管理塊的使用情況一樣����,我們也需要一個(gè) inode 位圖,來管理 inode 的使用情況�。我們就把 inode 位圖,放在 1 號塊吧����!同時(shí),我們把 inode 信息�,放在 2 號塊,一共存 8 條 inode����,這樣我們的 2 號塊就叫做 inode 表�。現(xiàn)在�����,我們的文件系統(tǒng)結(jié)構(gòu)���,變成了下面這個(gè)樣子�。注意:塊位圖是管理可用的塊��,每一位代表一個(gè)塊的使用與否���。inode 位圖管理的是一條一條的 inode�����,并不是 inode 所占用的塊��,比如上圖中有 8 條 inode�,則 inode 位圖中就有 8 位是管理他們的使用與否�����。
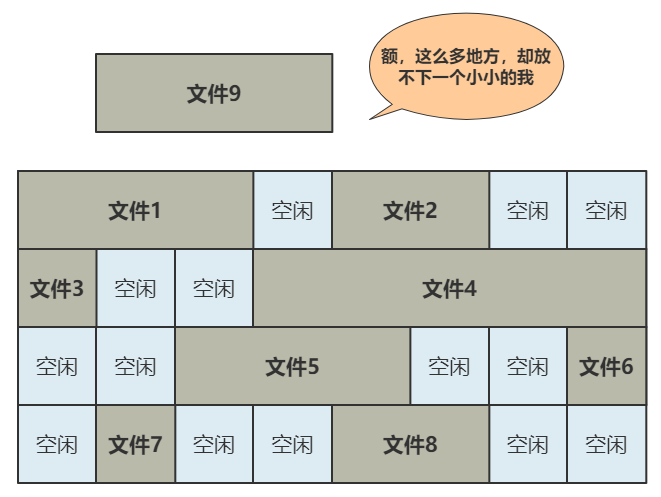
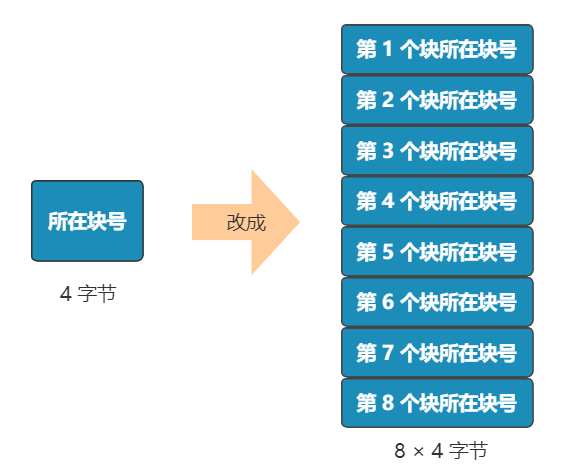
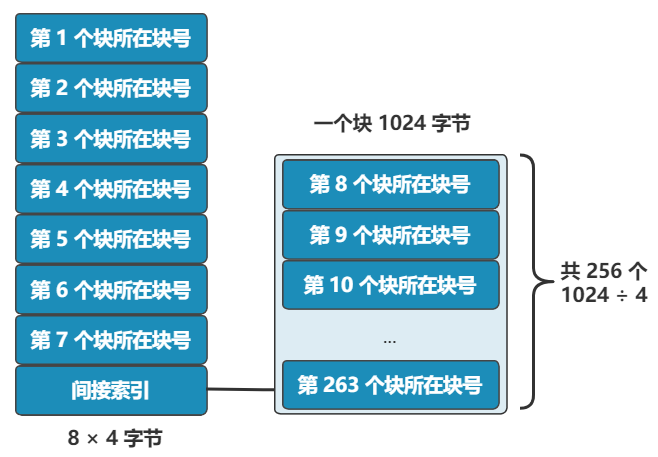
現(xiàn)在�,我們的文件很小,一個(gè)塊就能容下�����。但如果需要兩個(gè)塊����、三個(gè)塊、四個(gè)塊呢����?很簡單,我們只需要采用連續(xù)存儲法���,而 inode 則只記錄文件的第一個(gè)塊�����,以及后面還需要多少塊�����,即可��。這種辦法的缺點(diǎn)就是:容易留下大大小小的空洞�,新的文件到來以后,難以找到合適的空白塊�,空間會(huì)被浪費(fèi)。既然在 inode 中記錄了文件所在的塊號�,為什么不擴(kuò)展一下,多記錄幾塊呢�����?原來在 inode 中只記錄了一個(gè)塊號���,現(xiàn)在擴(kuò)展一下�,記錄 8 個(gè)塊號�����!而且這些塊不需要連續(xù)��。但是這也僅僅能表示 8 個(gè)塊�����,能記錄的最大文件是 8K(記住���,一個(gè)塊是 1K), 現(xiàn)在的文件輕松就超過這個(gè)限制了,這怎么辦��?很簡單�����,我們可以讓其中一個(gè)塊���,作為間接索引��。這樣瞬間就有 263 個(gè)塊(多了 256 -1 個(gè)塊)可用了�����,這種索引叫一級間接索引��。如果還嫌不夠�����,就再弄一個(gè)塊做一級間接索引����,或者做二級間接索引(二級間接索引則可以多出 256 * 256 - 1 個(gè)塊)。我們的文件系統(tǒng)�����,暫且先只弄一個(gè)一級間接索引���。硬盤一共才 1024 個(gè)塊�����,一個(gè)文件 263 個(gè)塊夠大了����。再大了不允許�,就這么任性,愛用不用。好了��,現(xiàn)在我們已經(jīng)可以保存很大的文件了��,并且可以通過文件名和文件大小��,將它們準(zhǔn)確讀取出來啦�!
但我們得精益求精�,我們再想想看這個(gè)文件系統(tǒng)有什么毛病。比如�,inode 數(shù)量不夠時(shí),我們是怎么得知的呢���?是不是需要在 inode 位圖中找�,找不到了才知道不夠用了����?同樣,對于塊數(shù)量不夠時(shí)��,也是如此�����。要是有個(gè)全局的地方,來記錄這一切�����,就好了����,也方便隨時(shí)調(diào)整,比如這樣
inode 數(shù)量
空閑 inode 數(shù)量
塊數(shù)量
空閑塊數(shù)量
那我們就再占用一個(gè)塊來存儲這些數(shù)據(jù)吧����!由于他們看起來像是站在上帝視角來描述這個(gè)文件系統(tǒng)的,所以我們把它放在最開始的塊上�����,并把它叫做超級塊��,現(xiàn)在的布局如下����。現(xiàn)在���,塊位圖����、inode 位圖、inode 表����,都是是固定地占據(jù)這塊 1、塊 2�����、塊 3 這三個(gè)位置�。假如之后 inode 的數(shù)量很多���,使得 inode 表或者 inode 位圖需要占據(jù)多個(gè)塊���,怎么辦?或者����,塊的數(shù)量增多(硬盤本身大了,或者每個(gè)塊變小了)��,塊位圖需要占據(jù)多個(gè)塊�,怎么辦����?程序是死的�����,你不告訴它哪個(gè)塊表示什么��,它可不會(huì)自己猜����。很簡單,與超級塊記錄信息一樣�,這些信息也選擇一個(gè)塊來記錄,就不怕了����。那我們就選擇緊跟在超級塊后面的 1 號塊來記錄這些信息吧,并把它稱之為塊描述符����。當(dāng)然,這些所在塊號只是記錄起始塊號���,塊位圖��、inode 位圖��、inode 表分別都可以占用多個(gè)塊����。
現(xiàn)在�����,我們再嘗試存入一批文件�。
誒�����?這看著好不爽����,所有的文件都是平鋪開的,能不能擁有層級關(guān)系呢�����?比如這樣
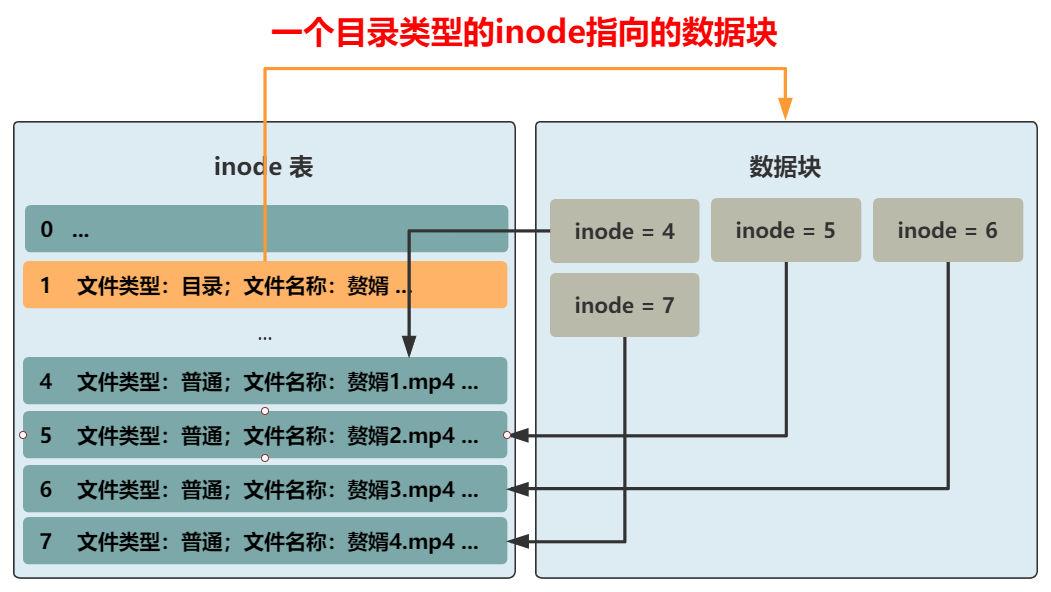
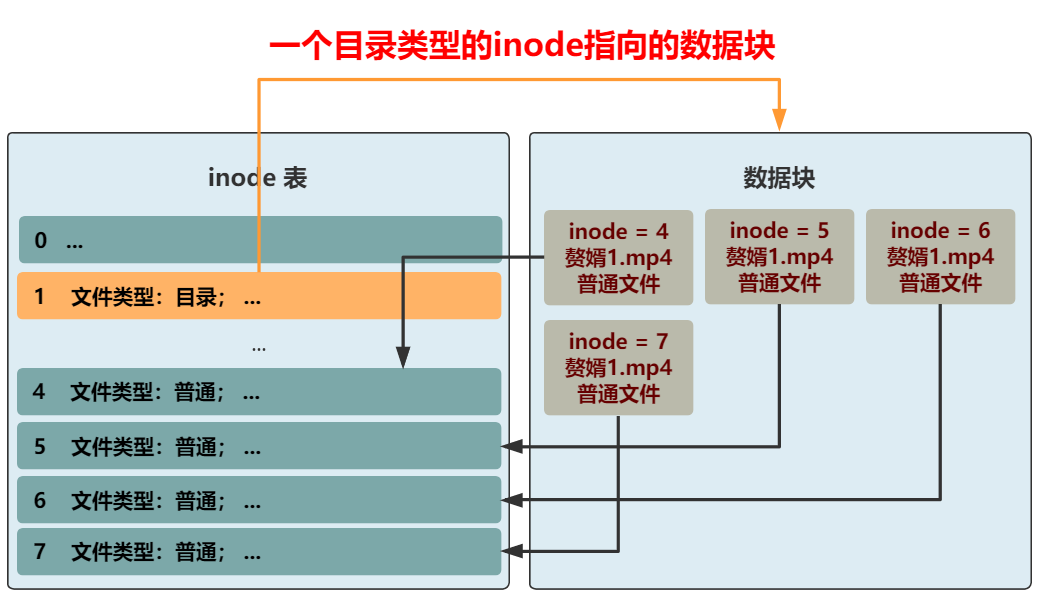
我們將葵花寶典.txt 這種稱為普通文件,將贅婿這種稱為目錄文件���,如果要訪問贅婿1.mp4����,那全文件名要寫成如何做到這一點(diǎn)呢?那我們又得把 inode 結(jié)構(gòu)拿出來說事了��。此時(shí)需要一個(gè)屬性來區(qū)分這個(gè)文件是普通文件�����,還是目錄文件�。缺什么就補(bǔ)什么嘛,我們已經(jīng)很熟悉了���,專門加一個(gè) 4 字節(jié)��,來表示文件類型�����。如果是普通文件��,則這個(gè) inode 所指向的數(shù)據(jù)塊仍然和之前一樣����,就是文件本身原封不動(dòng)的內(nèi)容。但如果是目錄文件�,則這個(gè) inode 所指向的數(shù)據(jù)塊,就需要重新規(guī)劃了���。這個(gè)數(shù)據(jù)塊里應(yīng)該是什么樣子呢���?可以是一個(gè)一個(gè)指向不同 inode 的緊挨著的結(jié)構(gòu)體,比如這樣�。這樣先通過 贅婿 這個(gè)目錄文件,找到所在的數(shù)據(jù)塊�。再根據(jù)這個(gè)數(shù)據(jù)塊里的一個(gè)個(gè)帶有 inode 信息的結(jié)構(gòu)體�����,找到這個(gè)目錄下的所有文件����。
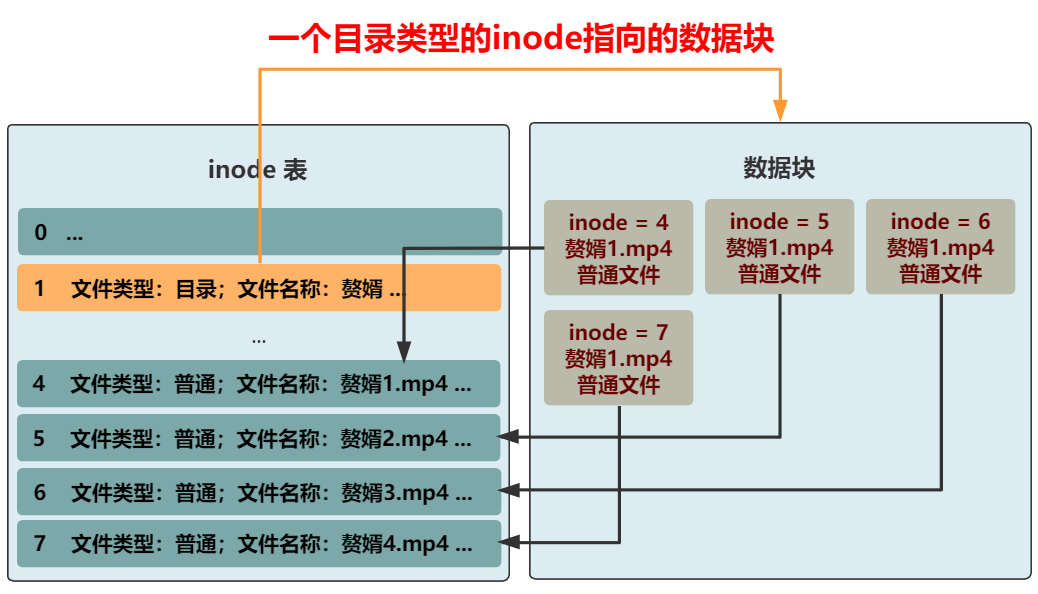
不過這樣的話����,你想想看�,如果想要查看一下贅婿這個(gè)目錄下的所有文件(比如 ll 命令),將文件名和文件類型都展示出來����,怎么辦呢?就需要把一個(gè)個(gè)結(jié)構(gòu)體指向的 inode 從 inode 表中取出���,再把文件名和文件類型取出�����,這很是浪費(fèi)時(shí)間�����。而讓用戶看到一個(gè)目錄下的所有文件�,又是一個(gè)極其常見的操作。所以����,不如把文件名和文件類型這種常見的信息,放在數(shù)據(jù)塊中的結(jié)構(gòu)體里吧��。同時(shí)���,inode 結(jié)構(gòu)中的文件名��,好像就沒啥用了�,這種變長的東西放在這種定長的結(jié)構(gòu)中本身就很討厭��,早就想給它去掉了���。而且還能給其他信息省下空間���,比如文件所在塊的數(shù)組,就能再多幾個(gè)了��。OK�����,大功告成����,現(xiàn)在我們就可以給文件分門別類放進(jìn)不同目錄下了��,還可以在目錄下創(chuàng)建目錄�,無限套娃!
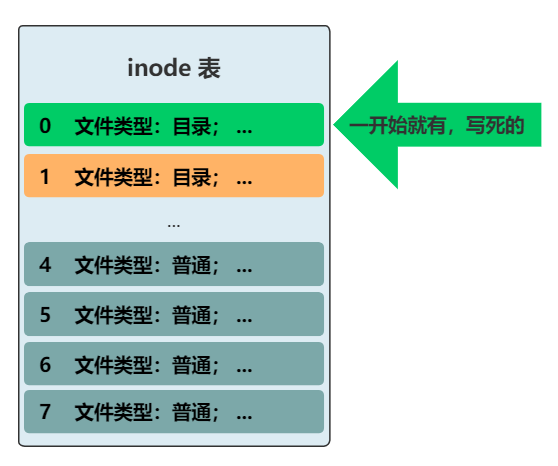
現(xiàn)在的文件系統(tǒng)�����,已經(jīng)比較完善了���,只是還有一點(diǎn)不太爽��。我們訪問到一個(gè)目錄下��,可以很舒服地看到目錄里的文件���,然后再根據(jù)名稱訪問這個(gè)目錄下的文件或者目錄,整個(gè)過程都是一個(gè)套路。但是�,最上層的目錄下的所有文件,即根目錄����,現(xiàn)在仍然需要通過遍歷所有的 inode 來獲得,能不能和上面的套路統(tǒng)一呢�����?答案非常簡單��,我們規(guī)定���,inode 表中的 0 號 inode��,就表示根目錄�����,一切的訪問�����,就從這個(gè)根目錄開始��!我們最后來欣賞下我們的文件系統(tǒng)架構(gòu)�����。
這個(gè)文件系統(tǒng)���,和 linux 上的經(jīng)典文件系統(tǒng) ext2 基本相同����。
下面是我畫的 ext2 文件系統(tǒng)的結(jié)構(gòu)(字段部分只畫了核心字段)
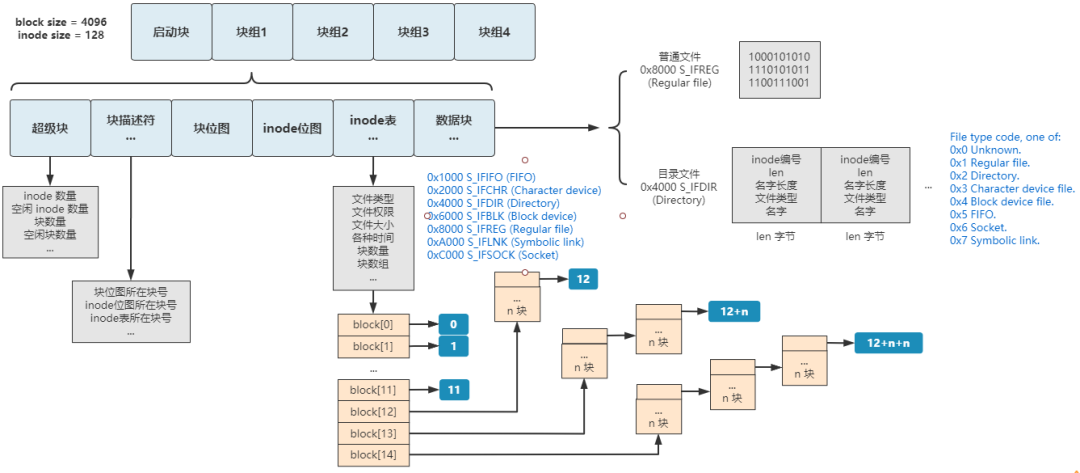
如果你想了解更多的細(xì)節(jié)��,可以參考官方說明文檔
https://www.nongnu.org/ext2-doc/ext2.pdf
你也可以用 linux 的 mke2fs 命令生成一個(gè) ext2 文件系統(tǒng)的磁盤鏡像��,然后一個(gè)字節(jié)一個(gè)字節(jié)地對照這官方說明文檔拆解��,這種方式其實(shí)是最直接的���。
來源微信公眾號:無聊的閃客
該文章在 2024/3/12 17:34:14 編輯過






 400 186 1886
400 186 1886
晴公司官網(wǎng)")