MSSQL數(shù)據(jù)分區(qū)
1. 什么是分區(qū)
在sqlserver中,一般情況下所有的數(shù)據(jù)都是存儲(chǔ)到一個(gè)文件上的(默認(rèn)為.mdf文件)����,這樣在數(shù)據(jù)非常多的時(shí)候效率肯定比較低。 而如果采用分區(qū)�����,數(shù)據(jù)就會(huì)按照我們指定的分區(qū)規(guī)則��,存儲(chǔ)到不同的文件��,這樣一來��,一個(gè)非常的大文件就被分成了多個(gè)小文件��,這樣一來查詢效率也會(huì)大大提升����。
如果我們不做任何分區(qū)�����,也就是說�,所有的數(shù)據(jù)都是存儲(chǔ)在主數(shù)據(jù)文件(.mdf)中的�����。 如果進(jìn)行了分區(qū)�����,那么我們就可以指定次要數(shù)據(jù)文件(.ndf)的數(shù)量��,來分?jǐn)傊鲾?shù)據(jù)文件的壓力�。除此之外,還有一個(gè)日志數(shù)據(jù)文件���,也就是(.ldf)文件���。
分區(qū)分為兩種,一種是水平分區(qū),另一種是垂直分區(qū)����。
水平分區(qū):對(duì)表的行進(jìn)行分區(qū)。每個(gè)物理區(qū)域保存一定量的行數(shù)據(jù)�,它們組合起來就是完整的表數(shù)據(jù)。進(jìn)行水平分區(qū)����,一定要指定某個(gè)屬性列進(jìn)行數(shù)據(jù)分割。比如:一年的訂單表可以按照時(shí)間分四個(gè)區(qū)(這里就是按照時(shí)間進(jìn)行數(shù)據(jù)分割的��。)
垂直分區(qū):對(duì)表的列進(jìn)行分區(qū)���。通過對(duì)表的垂直劃分來減少目標(biāo)表的寬度,使某些特定的列被劃分到特定的分區(qū)����,每個(gè)分區(qū)都包含了其中的列所對(duì)應(yīng)的行。
2. 準(zhǔn)備測(cè)試數(shù)據(jù)
在正式開始之前��,我們需要先創(chuàng)建一些數(shù)據(jù)�。創(chuàng)建了一個(gè)數(shù)據(jù)庫(kù)(mydb),和一張訂單表(order)�����,并且往訂單表中插入了1千萬(wàn)條測(cè)試數(shù)據(jù)。
create database mydb;
GO
use mydb
GO
create table order_detail
(
order_id bigint not null primary key nonclustered identity(1,1),
customer_id bigint not null,
goods_price decimal(10,2) not null,
create_time datetime not null,
);
GO
create clustered index create_time_clustered_index on order_detail(create_time)
GO
execute sp_addextendedproperty 'MS_Description', '訂單編號(hào)', 'user', 'dbo', 'table', 'order_detail', 'column', 'order_id';
execute sp_addextendedproperty 'MS_Description', '用戶id', 'user', 'dbo', 'table', 'order_detail', 'column', 'customer_id';
execute sp_addextendedproperty 'MS_Description', '商品數(shù)量', 'user', 'dbo', 'table', 'order_detail', 'column', 'goods_price';
execute sp_addextendedproperty 'MS_Description', '創(chuàng)建時(shí)間', 'user', 'dbo', 'table', 'order_detail', 'column', 'create_time';
GO
--插入1千萬(wàn)條數(shù)據(jù)�,大概需要15分鐘
declare @price_min Int=1 --測(cè)試數(shù)據(jù)最低價(jià)格
declare @price_max Int=1000000 --測(cè)試數(shù)據(jù)最高價(jià)格
declare @decimal Int=2 --價(jià)格保留小數(shù)點(diǎn)
declare @i int
set @i = 1
while @i < 10000000
begin
insert into order_detail(customer_id,goods_price,create_time)
values(
ABS(CHECKSUM(NEWID()))
,@price_min+round((@price_max-@price_min)*rand(),@decimal) --價(jià)格
,GETDATE()-(0.01*@i)/15); --插入時(shí)間,時(shí)間長(zhǎng)度大概是19年
set @i = @i + 1;
end
3. 如何進(jìn)行水平分區(qū)
在SQL Server中進(jìn)行水平分區(qū)的過程不是一個(gè)簡(jiǎn)單的SQL命令就可以搞定的����,它涉及到數(shù)據(jù)文件,文件組�����,分區(qū)函數(shù)��,和分區(qū)方案�����。 下面筆者將會(huì)把這個(gè)過程劃分成一個(gè)個(gè)的小步驟���,并且為每個(gè)步驟都做了較為詳細(xì)的解釋�����。
3.1 創(chuàng)建文件組
這個(gè)步驟的作用就是指定數(shù)據(jù)分區(qū)后要存儲(chǔ)的文件�。這里有兩個(gè)概念,一個(gè)是數(shù)據(jù)文件����,另一個(gè)是文件組,一個(gè)文件組可以管理多個(gè)數(shù)據(jù)文件�����,我們?cè)趧?chuàng)建分區(qū)方案的時(shí)候就需要指定這些文件組��。在創(chuàng)建分區(qū)完成后���,分區(qū)表中的數(shù)據(jù)會(huì)按照我們指定的規(guī)則分散地存儲(chǔ)到各個(gè)數(shù)據(jù)文件中����。
既可以在創(chuàng)建數(shù)據(jù)庫(kù)的時(shí)候創(chuàng)建文件組�,也可以在數(shù)據(jù)庫(kù)創(chuàng)建完成后再創(chuàng)建文件組�����。
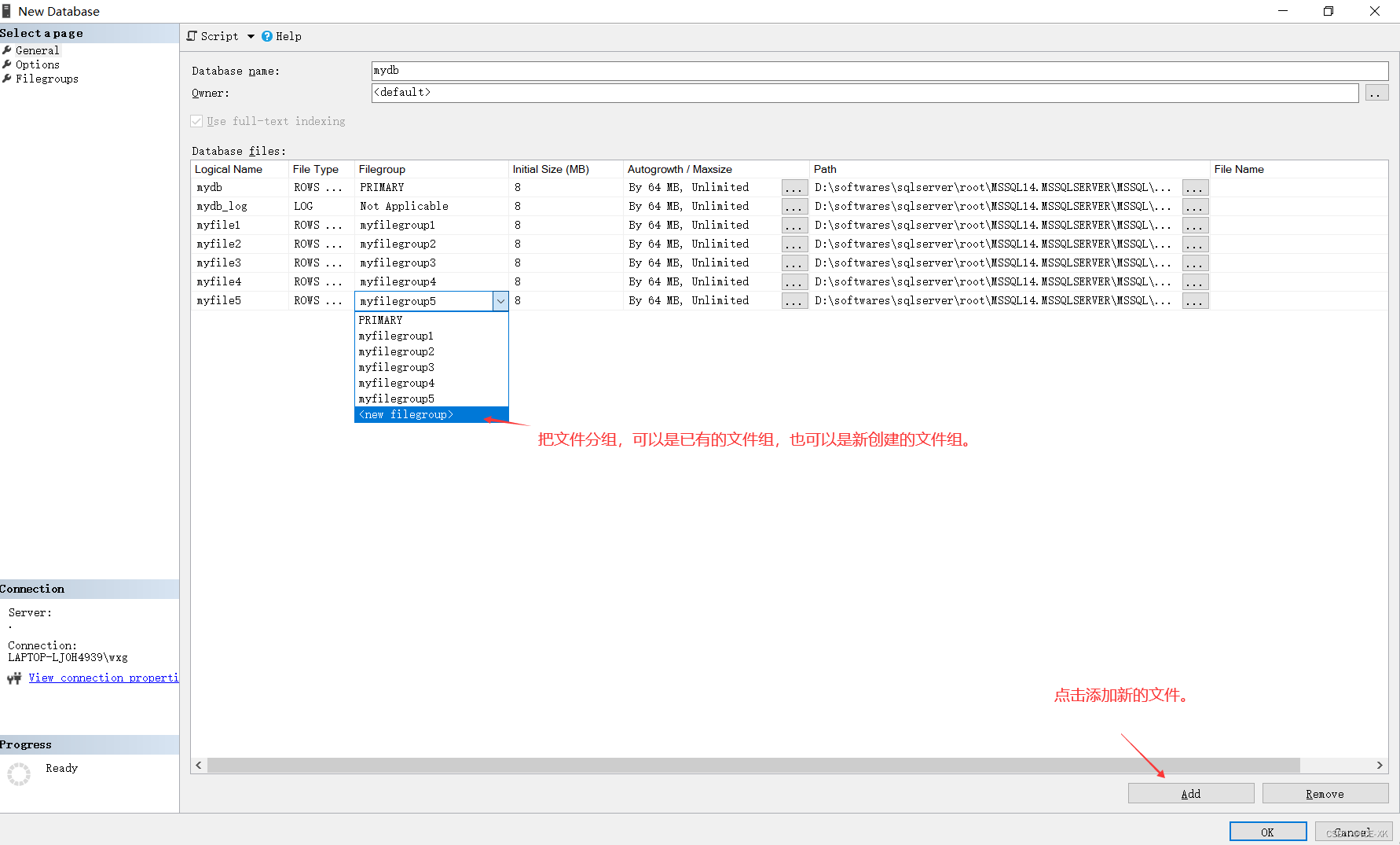
在創(chuàng)建完成數(shù)據(jù)庫(kù)后��,可以看到文件組可以被分為PRIMARY和你自定義的文件組兩種��。主數(shù)據(jù)文件(mydb)是屬于PRIMARY文件組,并且不能被改變�。myfile1,2,3,4,5是屬于次要數(shù)據(jù)文件,次要數(shù)據(jù)文件的歸組就比較隨意�����,既可以是PRIMARY����,也可以是你自定義的文件組。還有一個(gè)日志數(shù)據(jù)文件(mydb_log)不屬于任何文件組�。
創(chuàng)建完成后,打開你的數(shù)據(jù)存儲(chǔ)目錄��,可以看到SQL Server為你創(chuàng)建了如下文件��。

關(guān)于文件和文件組的更多信息����,可以移步到 Microsoft Database Files and Filegroups。
上面展示了在創(chuàng)建數(shù)據(jù)庫(kù)時(shí)候創(chuàng)建數(shù)據(jù)文件和文件組��。其實(shí)也可以數(shù)據(jù)庫(kù)創(chuàng)建完成后�,再創(chuàng)建數(shù)據(jù)文件和文件組。
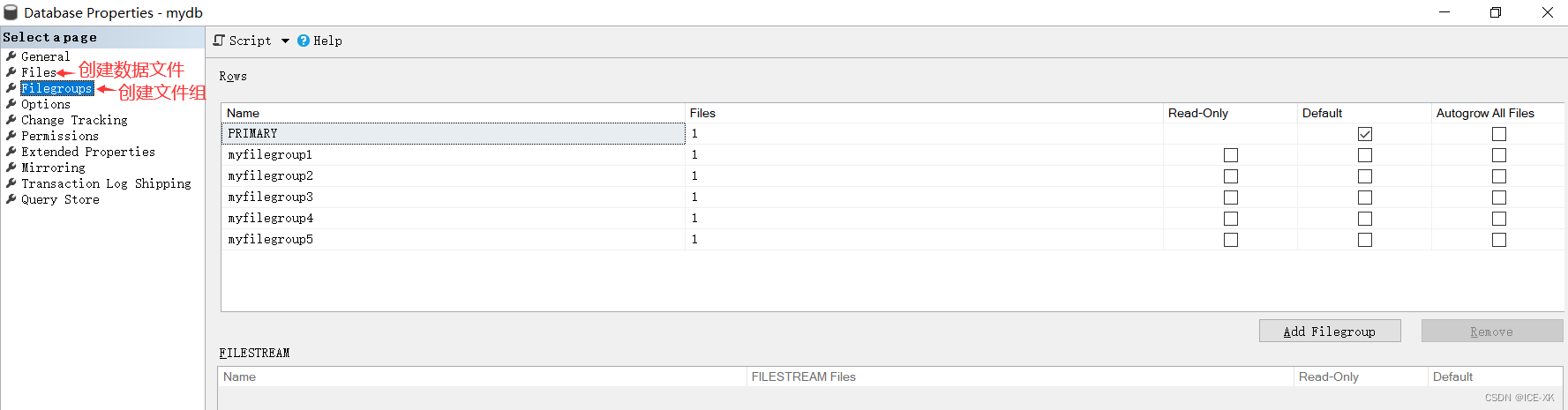
創(chuàng)建文件組
右鍵數(shù)據(jù)庫(kù) -> 屬性(Properties) -> 文件組(Filegroups)
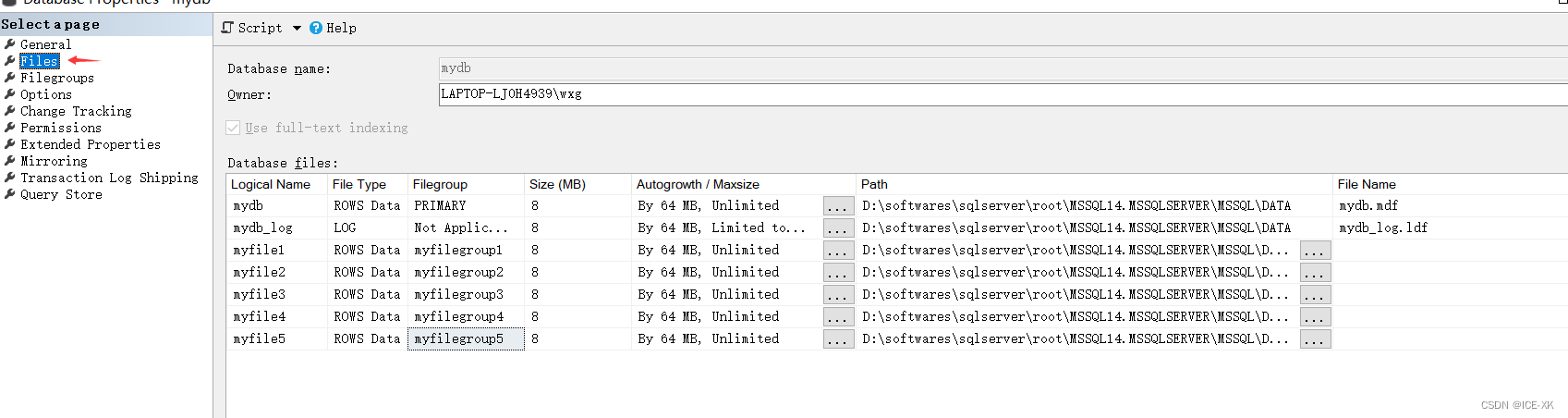
創(chuàng)建數(shù)據(jù)文件
右鍵數(shù)據(jù)庫(kù) -> 屬性(Properties) -> 文件組(Files)
通過T-SQL創(chuàng)建數(shù)據(jù)文件和文件組
你也可以通過T-SQL腳本來創(chuàng)建數(shù)據(jù)文件和文件組
--創(chuàng)建數(shù)據(jù)庫(kù)文件組
--alter database 數(shù)據(jù)庫(kù)名稱 add filegroup 文件組名稱
alter database mydb add filegroup myfilegroup1
alter database mydb add filegroup myfilegroup2
alter database mydb add filegroup myfilegroup3
alter database mydb add filegroup myfilegroup4
alter database mydb add filegroup myfilegroup5
--創(chuàng)建數(shù)據(jù)文件
--alter database 數(shù)據(jù)庫(kù)名稱 add file
--(name=N'文件名稱',filename=N'文件路徑',size=文件初始,filegrowth=文件自動(dòng)增量)
--to filegroup 文件組名稱
alter database mydb add file
(name=N'myfile1',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile1.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup1
alter database mydb add file
(name=N'myfile2',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile2.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup2
alter database mydb add file
(name=N'myfile3',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile3.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup3
alter database mydb add file
(name=N'myfile4',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile4.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup4
alter database mydb add file
(name=N'myfile5',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile5.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup5
3.2 創(chuàng)建分區(qū)函數(shù)
上面已經(jīng)創(chuàng)建了文件組�����,接下來就是創(chuàng)建分區(qū)函數(shù),分區(qū)函數(shù)是數(shù)據(jù)庫(kù)中的一個(gè)獨(dú)立對(duì)象��,它將表的行映射到一組分區(qū)�����,所以分區(qū)函數(shù)解決的是HOW的問題��,即表如何分區(qū)的問題����。
create partition function 分區(qū)函數(shù)名(<分區(qū)列類型>) as range [left/right] for values (每個(gè)分區(qū)的邊界值,....)
上面的left代表左邊界,right代表右邊界����。當(dāng) 數(shù)據(jù)庫(kù)引擎 按升序從左到右排序時(shí),邊界值是屬于左側(cè)還是右側(cè)(默認(rèn)為左側(cè))�����。換句話說���,就是一個(gè)為小于等于����,另一個(gè)為小于�����。
create partition function myPartitionFun(datetime) as range right for values ('2010-01-01 00:00:00','2017-01-01 00:00:00','2019-01-01 00:00:00','2020-01-01 00:00:00')
筆者數(shù)據(jù)庫(kù)中所有數(shù)據(jù)的時(shí)間范圍是2002到2020年��。上面的時(shí)間間隔是呈現(xiàn)錐形分布的����,之所以這么設(shè)計(jì),這是因?yàn)橛唵伪韺?duì)當(dāng)年發(fā)生的訂單的操作是最頻繁的��,其次是1年前的訂單(頻繁)�,再就是2-3年的訂單(操作比較頻繁),再則就是3-10年的訂單(操作偶爾發(fā)生)�����,最后是10年前的訂單(幾乎不再操作訂單)���,因此這個(gè)時(shí)間間隔是越來越大的�����。當(dāng)然如果有對(duì)所有數(shù)據(jù)都有較為頻繁的操作�����,可以分18個(gè)區(qū)(2002年到2020年)��,給每年都分區(qū)����。
3.3 創(chuàng)建分區(qū)方案
分區(qū)方案定義了一個(gè)特定的分區(qū)函數(shù)將使用的物理存儲(chǔ)結(jié)構(gòu)(就是文件組),或者說是分區(qū)方案將分區(qū)函數(shù)生成的分區(qū)映射到我們定義的一組文件組��。因此創(chuàng)建一個(gè)分區(qū)方案�����,需要分區(qū)函數(shù)和文件組名稱�。
create partition scheme <分區(qū)方案名稱> as partition <分區(qū)函數(shù)名稱> [all]to (文件組名稱,....)
我們已經(jīng)知道分區(qū)函數(shù)解決的就是HOW的問題, 而這個(gè)分區(qū)方案就是WHERE的問題�,它把分區(qū)函數(shù)生成的分區(qū)映射映射到指定的一組文件組中。
create partition scheme myPartitionSchema as partition myPartitionFun to (myfilegroup1,myfilegroup2,myfilegroup3,myfilegroup4,myfilegroup5);
分區(qū)函數(shù)生成的分區(qū)數(shù)不能大于分區(qū)方案中指定的文件組數(shù)量���。如果生成的分區(qū)數(shù)小于文件組的數(shù)量��,那么多出的文件組�,會(huì)被標(biāo)記為下次使用的文件組��。 myPartitionFun 指定了4臨界值因此會(huì)生成5個(gè)分區(qū)��, myPartitionSchema 恰好指定了5個(gè)文件組一一對(duì)應(yīng)5個(gè)分區(qū)���。
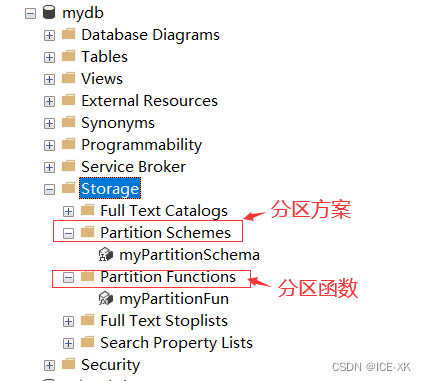
創(chuàng)建好分區(qū)方案后��,可以在數(shù)據(jù)庫(kù) -> 存ⅲ⊿torage) -> 分區(qū)方案(Partition Schemas)中查看
3.4 創(chuàng)建分區(qū)表
我們已經(jīng)創(chuàng)建了分區(qū)方案了����,接下來就是把分區(qū)方案應(yīng)用到數(shù)據(jù)表上���,這就是創(chuàng)建分區(qū)表��。
create table <表名> (
<列定義>
)on<分區(qū)方案名>(分區(qū)列名)
例如:
create table MyOrder
(
id bigint not null identity(1,1),
order_num nvarchar(32) not null,
order_status int not null,
createtime datetime not null,
updatetime datetime not null,
order_desc nvarchar(500) null
)
on myPartitionSchema(id);
上面是創(chuàng)建了一個(gè)新表���,并且指定了分區(qū)方案。由于在2.準(zhǔn)備測(cè)試數(shù)據(jù)中已經(jīng)創(chuàng)建了數(shù)據(jù)表��,因此這里我們?cè)俨恍枰陆ū?����,只需要將原來的表轉(zhuǎn)化為分區(qū)表就可以了。
將普通表轉(zhuǎn)化為分區(qū)表
分區(qū)表需要按照某一個(gè)字段把數(shù)據(jù)通過分區(qū)方案分到不同的文件中�,而這個(gè)作為分區(qū)條件的字段必需要有聚集索引才可以。之前創(chuàng)建的表 order_detail 的聚集索引是在 create_time 上的�,這里我們并不需要任何的修改。值得一提的是��,分區(qū)方案實(shí)際上是和聚集索引關(guān)聯(lián)的�����,而且如果你想要?jiǎng)?chuàng)建一個(gè)帶分區(qū)方案的聚集索引(也就是給表分區(qū))�,那么只有先刪除之前的聚集索引,然后再創(chuàng)建一個(gè)帶分區(qū)的聚集索引�。這種帶分區(qū)的聚集索引,也叫做分區(qū)索引��。
--刪除以前的聚集索引
DROP INDEX [create_time_clustered_index] ON [dbo].[order_detail] WITH ( ONLINE = OFF )
GO
--創(chuàng)建分區(qū)索引
CREATE CLUSTERED INDEX [create_time_clustered_index] ON [dbo].[order_detail]
(
create_time
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [myPartitionSchema]([create_time])
也可以通過向?qū)О哑胀ū磙D(zhuǎn)化為分區(qū)表
右鍵聚集索引 -> 屬性(Properties) -> 存儲(chǔ)(Storage)
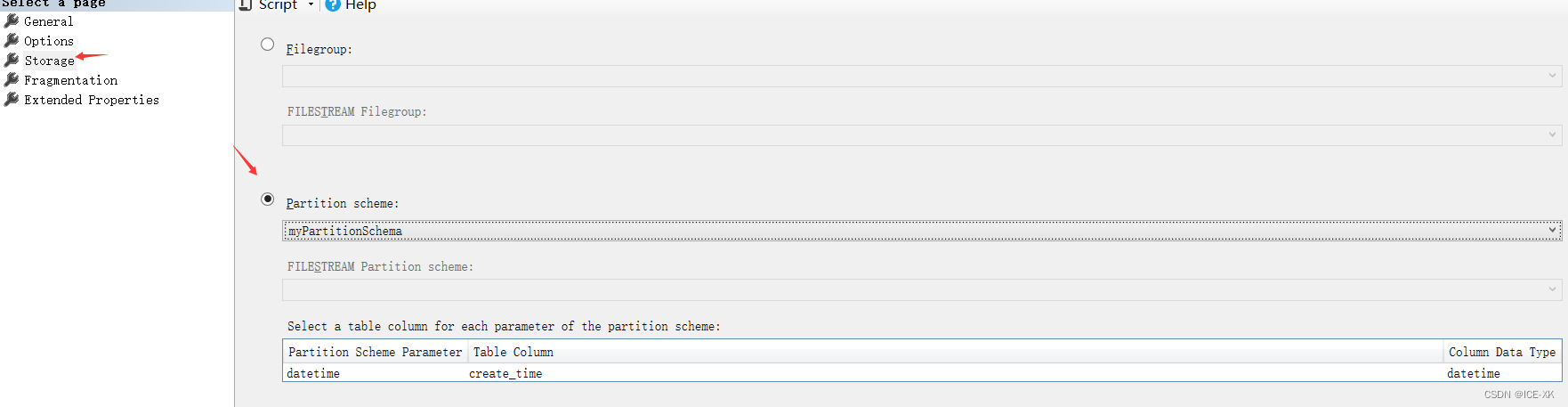
向?qū)?chuàng)建分區(qū)索引的過程也是顯示吧舊聚集索引刪除����,然后再創(chuàng)建一個(gè)新的聚集索引并且指定分區(qū)方案。
3.5 使用分區(qū)向?qū)?chuàng)建分區(qū)表
上面介紹的幾乎都是通過代碼實(shí)現(xiàn)的��,Microsoft SQL Server Management Studio 提供了更方便的圖形化方式��。
右鍵要分區(qū)的表 -> 存儲(chǔ)(Storage)-> 創(chuàng)建分區(qū)(Create Partition)-> 下一步
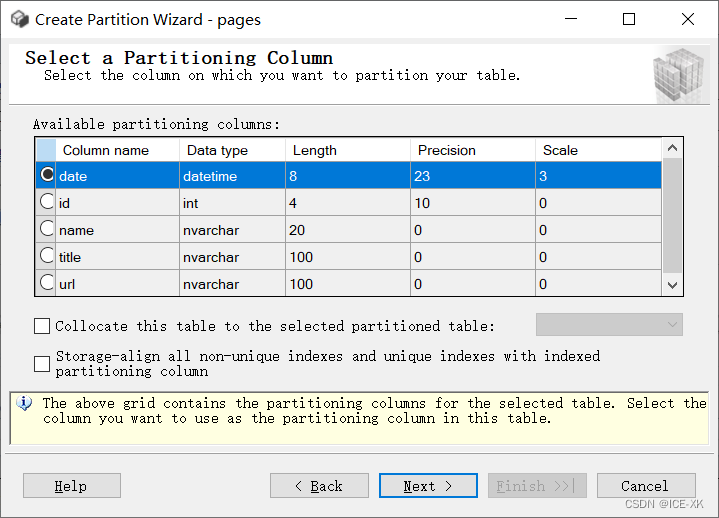
選擇要分區(qū)的列
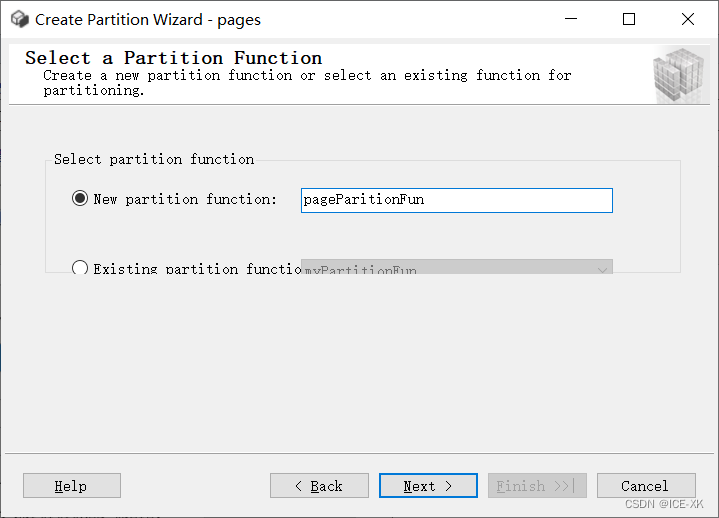
選擇或創(chuàng)建分區(qū)函數(shù)
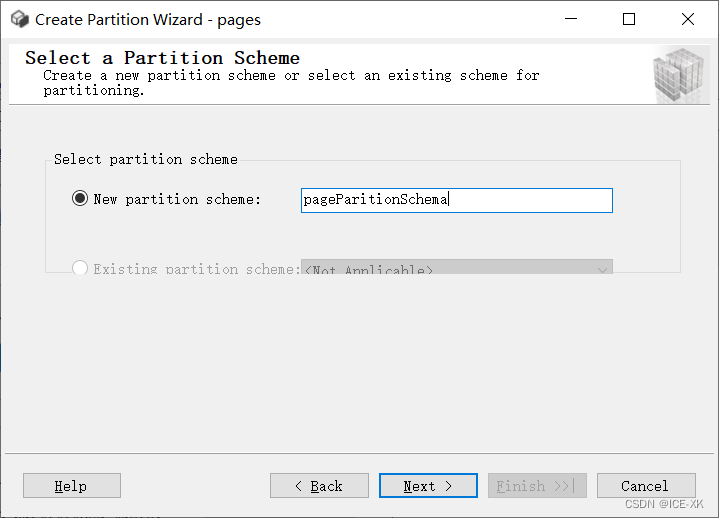
選擇或創(chuàng)建分區(qū)方案
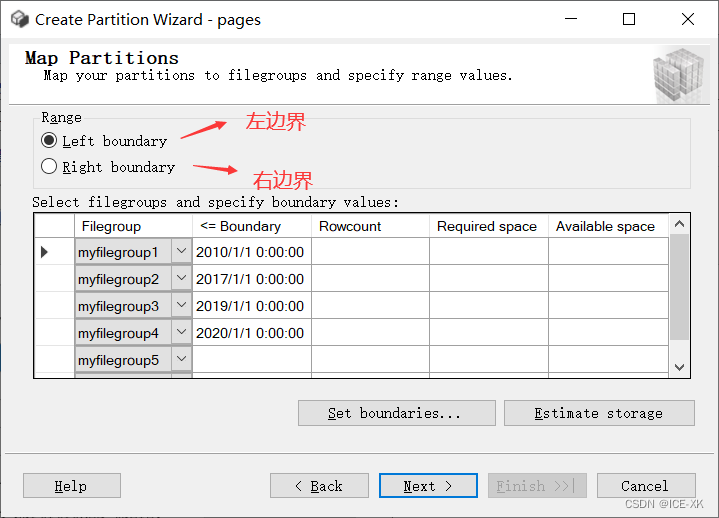
指定臨界值,以及左邊界或右邊界����。
3.6 秀一秀肌肉
到目前為止,分區(qū)表已經(jīng)創(chuàng)建完成了�����,接下來就是秀一秀它的性能了�����。我準(zhǔn)備了一張表 order_detail_non_partition �����,數(shù)據(jù)和索引都和 order_detail 表一樣��,只是 order_detail_non_partition 只是沒有分區(qū)�����。
--分區(qū)索引
select * from order_detail where create_time >= '2012-05-01 00:00:00' and create_time < '2019-06-01 00:00:00';
--無分區(qū)��,聚集索引
select * from order_detail_non_partition where create_time >= '2012-05-01 00:00:00' and create_time < '2019-06-01 00:00:00';
筆者的打開了SQL SERVER Management Studio中的實(shí)時(shí)數(shù)據(jù)查詢功能���。
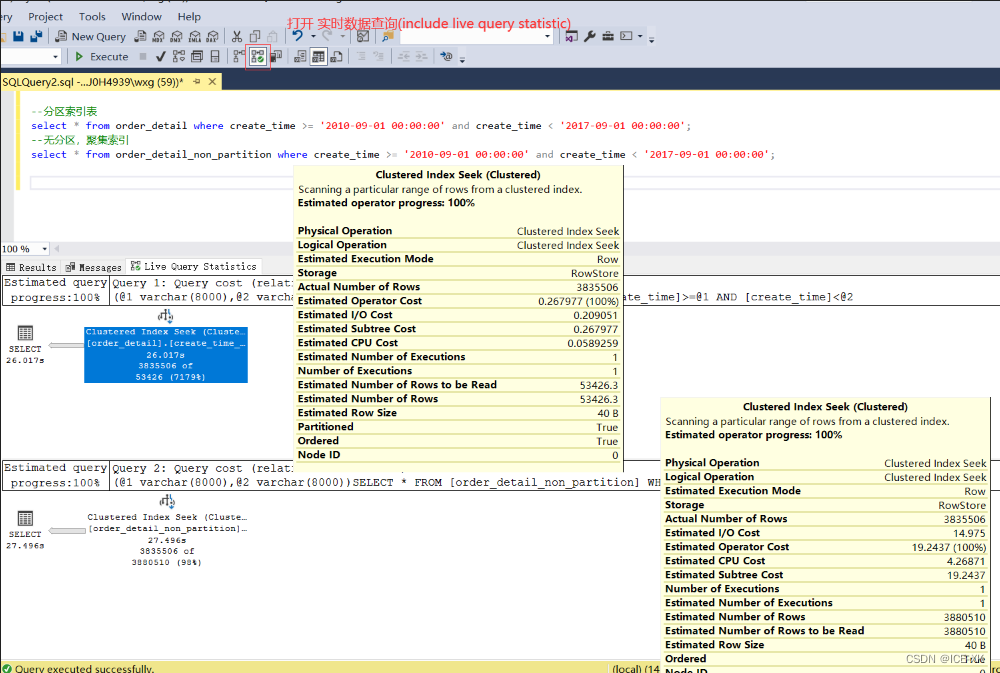
上面查詢了2010年7月份到2020年9月份的所有數(shù)據(jù)�����,雖然查詢所花費(fèi)的時(shí)間都差不多���,但是分區(qū)表在性能方面還是明顯優(yōu)于非分區(qū)表(I/O消耗,CPU消耗, 子樹的大小����,運(yùn)算符的開銷…)。
4. 關(guān)于表分區(qū)的常用管理
4.1 拆分分區(qū)
在分區(qū)函數(shù)中新增一個(gè)邊界值���。
--分區(qū)拆分
alter partition function myPartitionFun()
split range(N'2005-01-01T00:00:00.000')
如果分區(qū)函數(shù)已經(jīng)關(guān)聯(lián)了分區(qū)方案����,那么分區(qū)數(shù) 不能大于分區(qū)方案中的文件組數(shù)����。如果你的分區(qū)數(shù)和分區(qū)方案中的文件組數(shù)不符合要求,你可以先擴(kuò)展分區(qū)方案中的文件組數(shù)����,再擴(kuò)展分區(qū)函數(shù)的臨界值。
擴(kuò)展分區(qū)方案中的文件組數(shù)
--新建立一個(gè)數(shù)據(jù)文件
alter database mydb add filegroup myfilegroup6
GO
--新建一個(gè)文件組
alter database mydb add file
(name=N'myfile6',filename=N'D:\softwares\sqlserver\root\MSSQL14.MSSQLSERVER\MSSQL\DATA\myfile6.ndf',size=10Mb,filegrowth=5mb)
to filegroup myfilegroup6
GO
--添加文件組到分區(qū)方案
ALTER PARTITION SCHEME myPartitionSchema
NEXT USED myfilegroup6;
GO
4.2 合并分區(qū)
合并分區(qū)和拆分分區(qū)恰好相反,就是把兩個(gè)分區(qū)合并為一個(gè)分區(qū)�����,可以通過刪除分區(qū)函數(shù)中的臨界值來完成����。
--合并分區(qū)
alter partition function myPartitionFun()
merge range(N'2005-01-01T00:00:00.000')
4.3 查看指定數(shù)據(jù)所在的分區(qū)
當(dāng)進(jìn)行了表分區(qū)后,數(shù)據(jù)就會(huì)分散存儲(chǔ)到不同的分區(qū)中�??梢酝ㄟ^如下的命令,來查詢數(shù)據(jù)到底存到那個(gè)分區(qū)中的:
--查詢分區(qū)依據(jù)列為2020-08-28 14:34:02.890的數(shù)據(jù)在哪個(gè)分區(qū)上
select $partition.myPartitionFun(N'2020-08-28 14:34:02.890') --返回值是5�����,表示此值存在第5個(gè)分區(qū)
也可查詢所有非空分區(qū)中存在的數(shù)據(jù)行數(shù)
--查看分區(qū)表中�,每個(gè)非空分區(qū)存在的行數(shù)
select $partition.myPartitionFun(create_time) as partitionNum,count(*) as recordCount
from order_detail
group by $partition.myPartitionFun(create_time)
或是查詢某個(gè)分區(qū)中的所有數(shù)據(jù)
---查看指定分區(qū)中的數(shù)據(jù)記錄
select * from order_detail where $partition.myPartitionFun(create_time)=5
該文章在 2024/7/22 10:59:44 編輯過


晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")



 400 186 1886
400 186 1886
晴公司官網(wǎng)")

